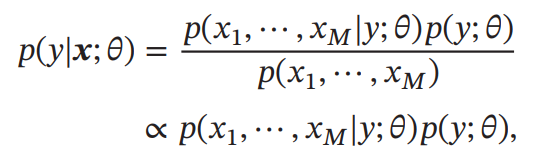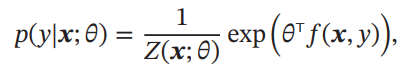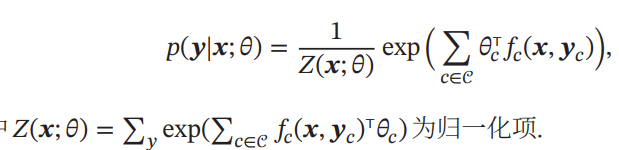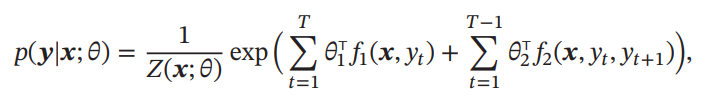中国の有名な機械学習の本の勉強ノート。自分がわからなかったところだけなので飛び飛びだろう。
https://nndl.github.io/
Graphical Modelとは、変数間の依存関係を定式化したもの。パラメタにすべて依存関係が存在するのであれば、大量にサンプリングしないといけない。これに対して、独立性の仮定を設ける。x1,⋯.xnに対して、
- x1を知っている前提で、x2,x3は独立である。
p(x2,x3∣x1)=p(x2∣x1)p(x3∣x1) - x2,x3を知っている前提で、x4とx1も独立である。
p(x1,x4∣x1,x3)=p(x1∣x2,x3)p(x4∣x2,x3) これを依存関係で構築すると、以下のようにできる。
p(x1,x2,x3,x4)=p(x1)p(x2∣x1)p(x3∣x1)p(x4∣x2,x3) Graphical Modelでは3つの基本的な問題がある。
- どのようにGraphical Modelで構成するか。
- どのようにパラメタを学習するか。
- 既知の変量をもって、どのようにほかの変量の確率分布を計算するか。
実際ほとんどの機械学習はGraphical Modelで表示することができる。それはそう。
例えば普通のCNNで識別するならば、X→yとなるし、中に隠れ変数hがあるならば、X→h→yというようになる。基本は一本線。
モデルの表現
有向グラフモデルと無向グラフモデルに分けられる。
- 有向グラフモデルの場合、DAGで構築される。A→Bはp(B∣A)となる。
- 無向グラフモデルの場合、無向グラフで作られる。辺があるということは依存関係があるが、どちらかが原因で結果かはわからない。
有向グラフィカルモデル
有向グラフィカルモデルは、Bayesian Network、Belief Networkとも呼ばれている。上で紹介したかたちが、有向グラフィカルモデル。
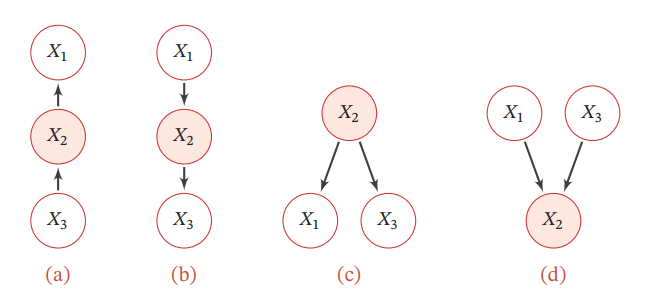
3つによる因果関係として、以下の4つの図のタイプがある。 背景に色がついているのは観測されているパラメタである。
aからcはすべて、X2が既知の時、X1,X3は条件付独立。
dだけ、X2が未知の時、X1,X3が独立だが、知ってしまったら独立ではなくなる。
局所的マルコフ性という性質がある。任意の変数について、1つの親接点が定まったら、すべての子接点以外のものとは条件付独立というもの。
有向グラフィカルモデルを実現するには
Sigmoid Belief Network(SBN)
変量がXk∈{0,1}をとる。親節点の集合はπkだとする。シグモイド関数をσで表す。条件確率分布は以下のようになる。
Pr(xk=1∣xπk;θ)=σ(θ0+∑xi∈Xπkθixi) つまり、線形モデルをSigmoidに入れた感じ。前にも同じような線形モデルによるcalibration=Logistic回帰があった。📄 NNDL 第3章 線形学習
NNDL 第3章 線形学習
学習するパラメタはθである。親節点の数がM個ならば、単純に2M個パターンの条件が生まれ概算が面倒である。だが上のようにパラメタ化することで、M+1個のパラメタで事足りる。
つまり、1つの頂点への入力をすべてまとめて1つのsigmoidのモデルで近似している。
1層のみ含むSigmoid Belief NetworkとLogistic回帰モデルの違いは、前者でxは非確定の変数で分布自体を推定して、生成モデルになれる、後者は確定の値で、分類モデルとなる。
Naive Bayes Classifier
ベイズの定理により、以下が成り立つ。
仮定として、Yが与えられたとき、Xm間はすべて条件付独立であるとする。この時、以下のようにp(y∣x)を分解できる。ここでθcは事前分布のパラメタであり、θmは条件分布のパラメタ。
p(y∣x;θ)∝p(y∣θc)∏m=1Mp(xm∣y;θm) 離散分布ならば、p(xm∣y;θm)は多項分布、連続分布ならばガウス分布でモデリングできる。
つまり、Graphical Modelの各Edgeごとに1つの分布を仮定し、独立性を仮定しているので積で計算している。
見るように、これは非常に強い独立性の仮定を設けているが、実用的にはNaive Bayes Classifierは悪くない結果を出す。
隠れマルコフモデル
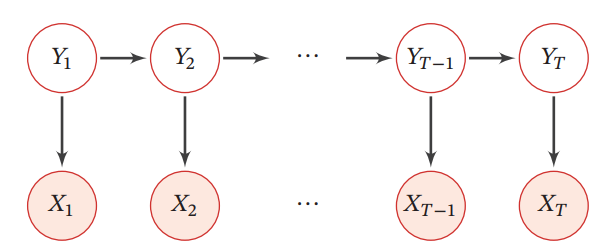
X1,⋯は観測可能な変量であり、Y1,⋯は隠れ変量である。これらはすべてマルコフチェーンを形成し、Xtの観測は当該時刻の隠れ変量Ytに依存するマルコフ過程に従う。
これを式で定義すると以下のようになる。X,Yはベクトルをつなげたもの。式の中では、ytをそれぞれどのように作っているか、そして各ytからxtができる確率を計算している。
p(X,Y;θ)=∏t=1Tp(yt∣yt−1,θs)p(xt∣yt,θt) p(xt∣yt,θt)は出力確率といい、p(yt∣yt−1,θs)は遷移確率という。
無向グラフィカルモデル
全体的な解説: https://www.slideshare.net/Kawamoto_Kazuhiko/ss-35483453
無向グラフィカルモデルはマルコフ確率場Markov Random Field(MRF)、Markov Networkとも呼ばれてる。
ランダム変量X1,⋯,XNについて、それを頂点とした無向グラフG=(V,E)を定義する。頂点v∈Vに対して隣接頂点をN(v)を定義する。この時、各頂点が局所的マルコフ性を満たす=隣接している頂点以外とは独立で関係がない。
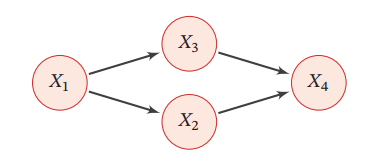
p(xk∣X¬k)=p(xk∣XN(k)) 上のようなグラフの場合、X2,X3が既知であるとき、X1とX4は互いに独立である。また、X1,X4が既知であるとき、X2とX3も互いに独立である。
無向グラフィカルモデルのクリーク分解
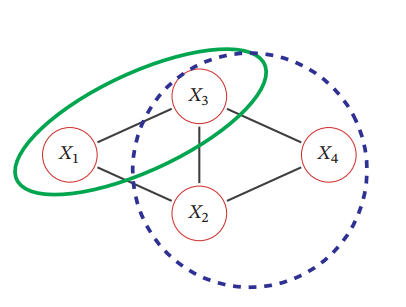
DAGではないので、トロポジカル分解はできない。その代わりに、Clique=クリークという、集合内のすべての頂点の間に辺がある=完全グラフというものに分解していく。上の図の場合、以下のようなクリークを持つ。
(X1,X2),(X1,X3),(X2,X4),(X3,X4),(X2,X3),(X1,X2,X3),(X4,X2,X3) その中で、極大のCliqueに着目する。他に何かの頂点を加えてもCliqueを新たに作れない=極大Clique。この時、別にクリークのサイズが最大と等しいわけではないことに注意!上図の例だと、(X1,X2,X3),(X2,X3,X4)が極大クリークの集合。
そして、無向グラフィカルモデルの分解を以下のように定める。
- 与えられた無向グラフの極大クリークの集合をC(1つとは限らないので)とする。
- 最大クリークの集合ではない!極大クリークとは、任意の頂点を加えてもより大きいクリークを作ることができないクリークの集合。
- クリークcについて、ϕc(xc)はPotential Functionという。
- 各クリークごとに変わる势能函数Potential Functionに頂点を代入している。
- 一般的に使われるのはギブス分布。量子力学のルールで習慣的にマイナスをつけているだけ。Ecによって毎回変換しているといえる。
ϕc(xc)=exp(−Ec(xc)) - ZはPartition Functionであり、総積を確率化したいから割っている。
p(x)=Z1∏c∈Cϕc(xc)Z=∑x∈X∏c∈Cϕc(x) もしギブス分布に従うと定義するのならば、以下のように書くことができ、それはボルツマン分布というもの。
p(x)=Z1∏c∈Cexp(−Ec(xc))=Z1exp(−∑c∈CEc(xc)) このようにモデリングするのが普通である。
一般的な無向グラフィカルモデルを実現するには
対数線形モデル
Potential Functionを以下のように定義する。
ϕc(xc∣θc)=exp(θcTfc(xc)) fc(xc)はxcの特徴量を抽出しているといえる。
このように定義すると、グラフィカルモデル全体の対数確率は以下のようになる。
logp(x∣Θ)=∑c∈CθcTfc(xc)−logZ(Θ) このモデルを用いて、p(y∣x)を予測する場合は以下のようになる。
このモデルでは、X,yの間の関係は以下のようになる。
Conditional Random Field(CRF)
解説: https://mieruca-ai.com/ai/conditional-random-fields/
上の対数線形モデルでは、yは定数であったが、そのyすら確率変数となるときが、Conditional Random Fieldである。p(y∣x;θ)は上のセクションのようなギブス分布で定義するとして、以下のようにp(y∣x;θ)を得ることができる。
この上の式は、すべてのクリーク内での対数線形モデルの総和である。
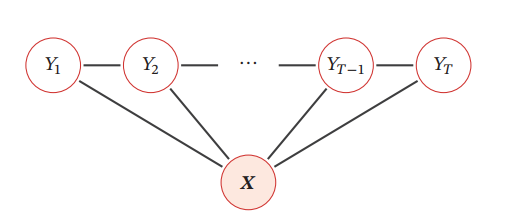
そして、CRFについてグラフをどのように書くかはいろんな定義があるが、最もよく使われるのは以下のようなLinear Chain CRFである。
存在するクリークは(Y1,Y2),(Y2,Y3)などや(Y1,Y2,X),(Y2,Y3,X)などの3つ組であり、後者が最大クリークなので、後者に着目する。
(Y1,Y2,X)について、(Y1,Y2)の関係はf2(x,y1,y2)でとらえてこれは遷移特徴、(Y1,X),(Y2,X)の関係はf1(x,yi)でとらえて状態特徴という。
よって、最大クリーク全体についてイテレーションすると以下のようになる。ここで、(Y2,X),(Y4,X)などは各クリークから2回ずつ呼ばれるが、どうせパラメタと内積をとるので1つにまとめていい。なので以下のようになる。
有向と無向の間の転換
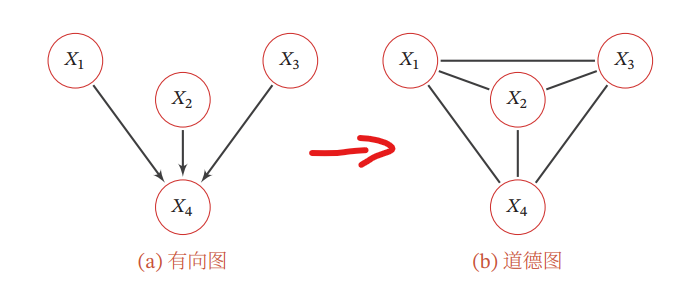
無向から有向に直すのは難しいが、有向を無向に直すのは簡単である。
無向は最大クリークで見るので、1つの最大クリークの中に収める必要がある。このために辺を追加することになるが、それをMoralizationという。
グラフィカルモデルの学習