
前回はこれ。
強化学習の各種
Bellman Equation
参考資料: https://qiita.com/triwave33/items/5e13e03d4d76b71bc802
Value Function
状態からポリシーに沿って得られる利得の条件付期待値を以下のように定義する。これはState-Value Function。これで、状態にいるときの価値というのを定義できる。価値は未来永劫にわたって得られる利益の和(さすがに発散するのでの係数を毎回かける)
似たように、状態のみならず、行動までわかっているときの期待値はAction-Value Functionという。
もし、がわかっているなら、最適なポリシーは毎回を選ぶこと。これは常に決定的である。
そして、2つの式の間では以下の関係が成り立つ。すべて合算する感じなのでそれはそう。
Bellman Equationを導入する
以下のような式変形で、
- 状態からのポリシーに従って得られるActionのの期待値
- 今の状態と取るActionからの次の状態の期待値。
についての期待値として、記述することができる。

- 真ん中の説明へ遷移したときの得られる利得。
- 右はであり、次のState Valueである。
毎回の利得はが条件付きで成り立つ。これをもとに、ポリシーを期待値に分解すると、上に述べた2つの総和となり、加算される。そして期待値の中は漸化式で再帰的に同じものが現れる。
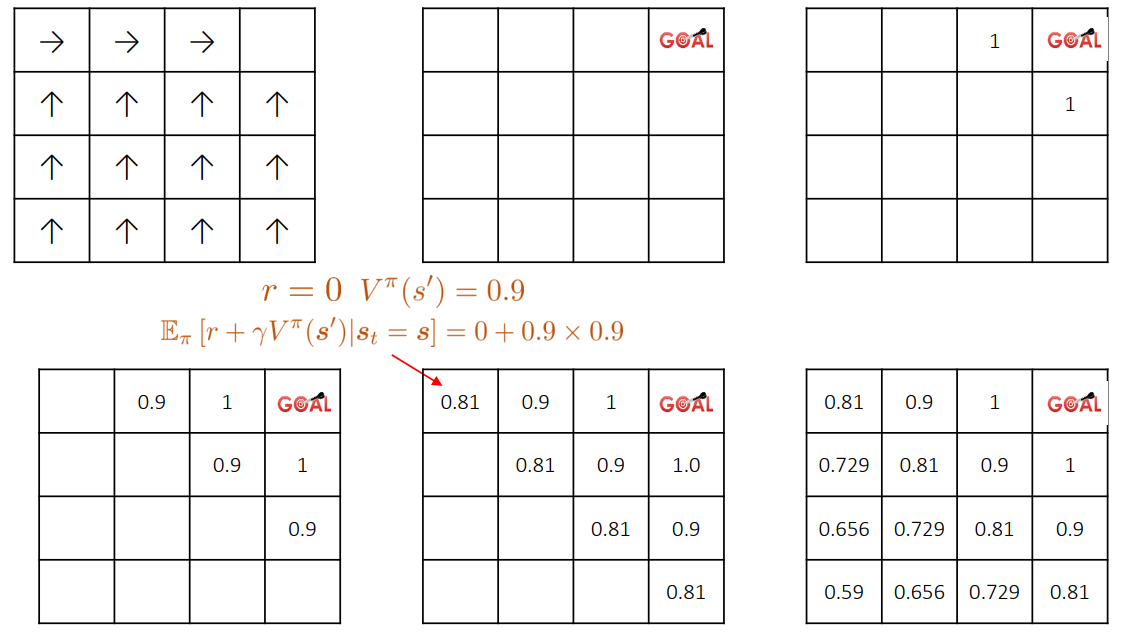
上があるポリシーに従った各状態=地点における価値である。
SARSA
Bellman Equationを利用したOn-policy(=今集めているデータからわかる状況で、次のアクションを決定する。→決めたアクションをもとに、データを収集する)推測である。
次の目的関数を最小化したい。
つまり、今いる時点での価値と、動いた後に得られる価値と将来の価値に減衰率を乗じたものと一致させたいように学習する。
なお、Gradientは以下のようになる。
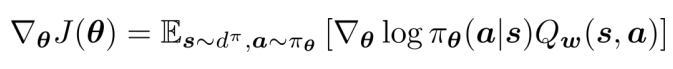
Bellman Operator
Bellman Operatorとは、Action Value Functionについての将来を漸化式のように予測したものである。
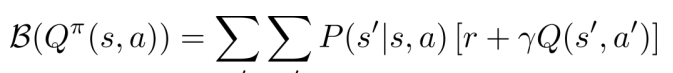
Bellman Operatorによって最適なポリシーに収束するらしい。
Optimal Value Function
さっきのValue Functionに対して、最適なポリシーを与えたときの関数。である。
そしてそれは1つだけActionを選ぶので、通常のを代入して展開するのと同じように、による漸化式になる。
Q-learning
最適なaction-value functionのを見つけたい。そのために、以下の式で学習をする。
Bellman Equationで得られた今後のOptimalなPolicyをとった時の予測と、実際にActionので得られた報酬の差を、一定の学習率で更新させていく。
Replay Buffer
強化学習で遷移情報を集めるときに、そのまま使うと自己相関があまりにも強すぎるので(前後するフレームなので)、それを使わずにまずはReplay Bufferにためておく。そして、学習時はReplay Bufferから溜まっているサンプルをランダムに選択して、ミニバッチを作成する。これは以下のDQNの性能に大きく貢献している部分でもある。
Deep Q-learning
参考: https://qiita.com/wing_man/items/a9cb43711dbb188f1604
まず、最大化したい期待利得関数を選ぶ。とする。
次に環境から行動をとった時に次にどんな環境に移り、その利得がどうなっていたかのデータを集める。
以下の式でに二乗誤差を最小化させる。

表現力が豊かなNNを使って、を作る。ただ問題点として、再帰的な式であるように、普通にやると正解に収束することを保証するのは難しい。学習したい関数のラベルに自身が大いにかかわっているから。
使うのは普通の全結合層のNNであるらしい。
Prioritized Experience Replay
参考: https://qiita.com/fujitagodai4/items/62100d63b43cd518c127
Replay Bufferからサンプルを選ぶとき、ランダムに選択するのではなく、TD誤差が多いサンプルを選ぶ。
まず、データがサンプリングされる確率を考える。ハイパーパラメタでありこれが0へ収束すると、一様分布になる。
は次のように決定する。微小なとして、以下のようにする。
TD誤差とはである。つまり、Q値の予測のズレが大きいほど、選ばれやすい=優先して学習することになる。
Noisy Networks for Exploration
参考: https://jsapachehtml.hatenablog.com/entry/2018/10/13/173303
ε-greedyについて改良した手法。通常の線形の計算に対して、パラメタのにノイズが入ることを考える。は各要素ごとの積。
はノイズで毎回学習のたびに変わる。学習するパラメタはである。
このように線形の計算をDQNの最後の全結合層にしている。
A distributional perspective on reinforcement learning
参考: https://qiita.com/keisuke-nakata/items/2767c287e4ee7a71716c
強化学習において、収益の 期待値 ではなく、その 分布 が有用であることを主張している。
ようわからん スキップ
Distributional Reinforcement Learning with Quantile Regression
参考: https://qiita.com/ku2482/items/504ad60c8146ca9a1858
わからん