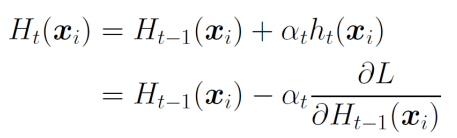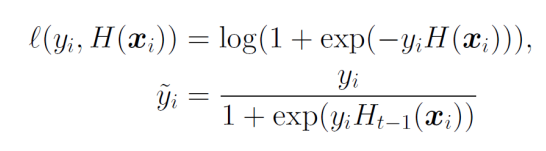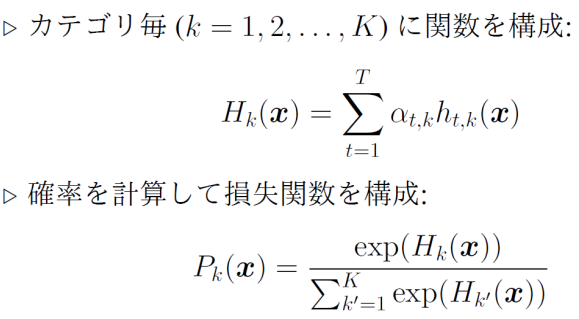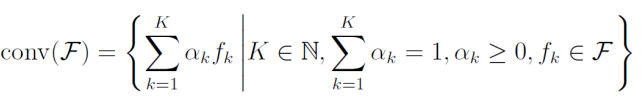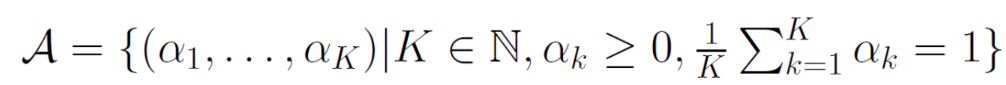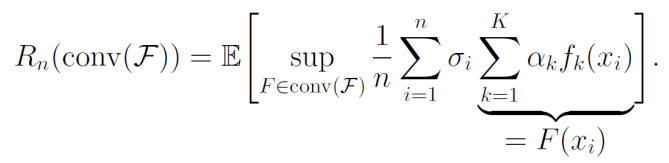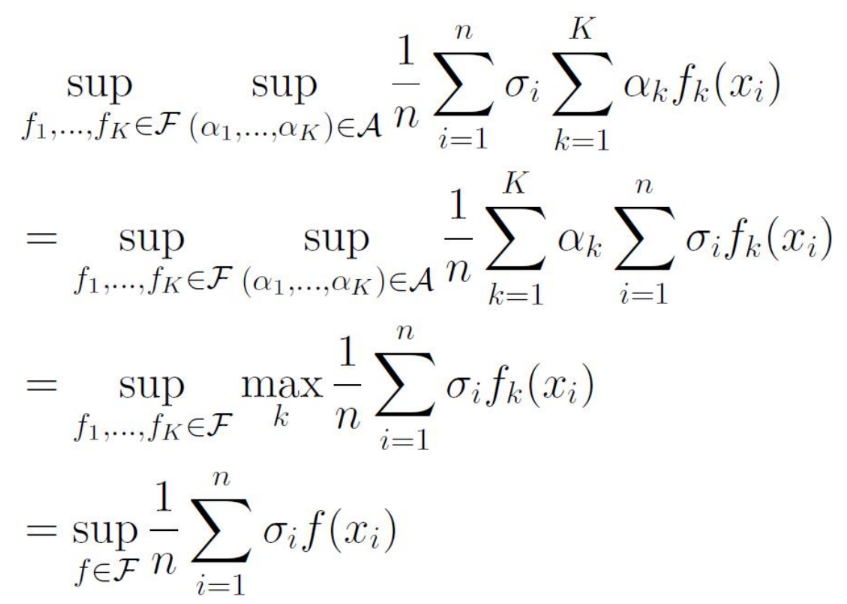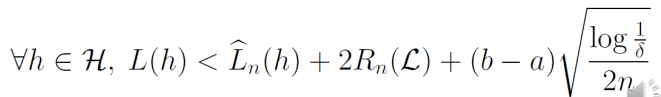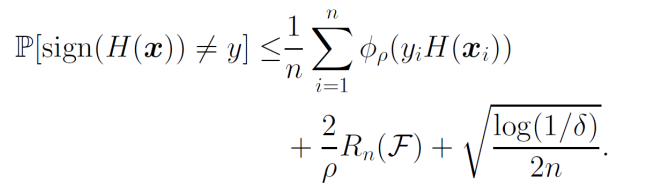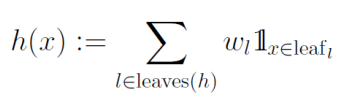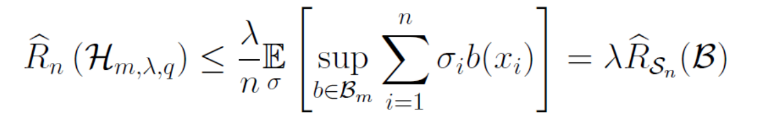前回はこちら。📄 (講義ノート)統計的機械学習第8回 。内容は以下の通り。
(講義ノート)統計的機械学習第8回 。内容は以下の通り。
多クラス分析の汎化誤差解析
これはよくない上界であり、よりよい上界の評価だと、1−δ以上の確率で以下のようになる。
Rn(ϕρ∘M)≤ρ4∣Y∣Rn(F′)+2mlog(1/δ) 今回は、そこまで効率的ではないアルゴリズムであっても、数を集めるとうまく学習できるというBoostingについてである。
確率的近似学習
Probability Approximately Correct learning=PAC学習というものがある。
ある真の仮説h∗がPAC学習可能であるとは、∀ϵ,∀δについて、以下を満たす仮説hを出力する多項式時間アルゴリズムが存在すること。
Pr(Pr(h=h∗(x))>ϵ)≤1−δ うまく仮説を見つける多項式アルゴリズムがあればOK。
Boostingについて
まず、弱学習器について定義する。
先ほどのPAC学習で∀ϵ,∀δで成立するということだった。これを∃ϵ.∃δという、ある固定された2つの値で学習できる学習器のことである。
この弱学習器があるなら、PAC学習可能な学習器はできるか?→できます!
Boostingは何するの?
複数の識別器による重み付き(もちろんすべて重みが同じでもいい)の識別器による多数決をするアルゴリズムであること。
線形で分離不能であるとしても、多数決のシステムを導入すれば非線形も学ぶことができる。
- バギング t個目の識別器の訓練に使うデータは、全体のデータDからサンプリングして選ぶ。
- ブースティング t個目の識別器の訓練に使うデータは、全体のデータDだけではなく、今までの識別器f1,⋯,ft−1を参考にして作る。
📄NNDL 第9章 教師なし学習 も参考にする。
Gradient Boosting
回帰について考える。
- 観測データ{(xi,yi)}i=1nである。
- 弱識別器はh:X→R
集団学習における回帰問題は、以下のように重みαtを割り当てて、弱学習器htを選ぶ。ではどう決めるのか?
yi=H(xi)=∑i=1Tαtht(xi) 弱学習器を追加するときに、追加した結果できるだけyiに近づいてほしい。
∀i,yi≈Ht−1(xi)+αtht(xi)∀i,yi−Ht−1(xi)≈αtht(xi) よって、次の弱学習器は、残差yi−Ht−1(xi)を学習するようにすればいい。
学習器Ht−1について損失関数を以下のように、MSEによる回帰の形にする。
L(Ht−1)=∑i=1nl(yi,Ht−1(xi))=21∑i=1n(yi−Ht−1(xi))2 ここで、xiを固定して微分を考えると、以下のようになる。
∂Ht−1(xi)∂L(Ht−1)=Ht−1(xi)−yi ここで、以下のようなhtを選ぶとする。
ht(xi)=yi−Ht−1(xi)=−∂Ht−1(xi)∂L そうすると、Ht(xi)=Ht−1(xi)+αtht(xi)へ代入をしてみると、以下のようにまさに勾配法になる。
なので、1ステップ前の関数で勾配法を適用させることで、自動的に残差を学習できる。
逆に言えば、htがわかれば、それがGradientの負符号になる。実際はそこまで理想的なhtを得ることはできないので以下のように計算される。
ht=argminh∈H21∑i=1n(yi−Ht−1(xi)−h(xi))2 なので、具体的には以下のようになる。損失関数が2乗誤差である必要がなく、2乗誤差であれば微分したらちょうど残差になりより数学的には推定の精度が上がるというだけである。
- 損失に対して、Ht−1についての勾配を計算する。
y~i=−[∂Ht−1(xi)∂l(yi,H(xi))]H=Ht−1 - その勾配y~iにできるだけフィッティングするような関数を探す。y−Ht−1(xi)は残差であり、MSEを使うならば今探しているh(xi)はその解である。
ht=argminh∈H21∑i=1n(yi−Ht−1(xi)−h(xi))2 - 更新するstep sizeを計算する。これは一意に決められる。
αt=argminαL(Ht−1+αht) - Ht=Ht−1+αthtで更新する。
二乗損失の代わりに他使うとどうなるか
二乗損失では、微分すると残差になる。
絶対損失では、劣微分するとy~i=sign(yi−Ht−1(xi))となる。つまり残差の符号になる。
ロジスティック損失では、以下のようになる。
分類の場合はどうすればいいか
これは回帰についての手法なので、分類に適用するときは以下のようにする必要がある。
カテゴリごとに、所属している=0、所属していない=1を予測するように(onehotの予測のように)する。
それか、softmax化させたものを損失関数で予測する。
Boostingの汎化誤差解析
凸包
まず、凸包を定義する。これは該当のk個の仮説について重みを割り当て、その重みの和が1になるようなときに作った識別器の集合のこと。
凸包のRademacher複雑度は、もともとのRademacher複雑度と等しい。
Rn(conv(F))=Rn(F) 証明はこちら
まず、次のような集合を考える。
このような集合を考える。これを重みに用いて、以下のようにRademacher複雑度で展開できる。
ここでのsupのconv(F)をかきかえることができる。sup(α1,⋯)∈Asup(f1,⋯)∈Fとなる。
このように、σi,αiの順序を交換してみると、supαは一番大きい所だけαi=1,それ以外は0にすればよく、それはつまりmaxを取るのと変わらない。
この操作をすれば、おのずと当初のRademacher複雑度Rn(F)が得られる。
汎化解析
弱学習器の集合をFとする。Boostingの仮説関数H(x)=∑t=1Tαtht(x)として、その集合をHとする。
ここではαtの非負、和が1を満たす必要がある。Boostingによってはそうじゃないものもあるので、もし重みが負ならば∀h,−h∈Fとすればいい。和自体は正規化してもいいので正規化する。
Rademacher複雑度による汎化誤差解析は以下のようになっていた。
これを利用すると、以下のようになる。
∀ρ>0に対して、1−δ以上の確率で以下が成り立つ。
ここで、ϕρ=1(yiH(xi))≤exp(−yiH(xi))を用いれば、AdaBoostの汎化誤差解析ができる。ここで使っている−expは非常に誤差に対して厳しいものである。
これの証明自体はほぼ自明であるので、書かない。Taraglandの補題と、01損失をϕρ=1を使って上から押さえられるというのを使う。
Decision Stamp(決定株)のRademacher複雑度
定義
仮説関数は、ある閾値zを引いた時の符号にα=+1,−1を乗じたもので、これは弱識別器である。そして、kクラス分類であるので、識別器はd,k∈[1,d]個ありその中での最大値を取るクラスを識別結果とする。
証明
形からして、Massartの有限仮説の補題を使いそう。
まず、Hはzが無限に値をとれるので無限集合のように見える。しかし、α,dは有限であり、各データ点は有限であるので、取りうる意味があるzは高々意味のあるn+1通りしかない。なので、実はHは有限集合であり、以下のMassartの有限仮説の補題を使える。
∃M≥0,supa∈A∑i=1nai2≤M2Eσ[supa∈An1∑i=1nσiai]≤n2M2log∣A∣ そして、∣H∣=2×d×(n+1)であり、取りうるデータ点が∣M∣=1であるとすれば、示せた。
XGBoost/LightGBM
テーブルデータに強い。
回帰木と呼ばれる実数値を出力する木のアンサンブルをする。
回帰木は+1,−1に限らず、連続値を出力する。
XGBoostのRademacher複雑度
Gradient Boostingのアルゴリズムに落とし込んで考えると、
こんな風にやりたい。ここにあるh(xi)は回帰木である。
回帰木
まずは回帰木について定義する。
各葉leaflは値wlを持つ。入力xを、葉のいずれかに対応付けるノード分割関数(左に行くか右に行くかのように)を決定木で実装する。
そして、葉の出力については、入力xが分類の末にたどり着いた葉leaflに入っているなら1、入っていないなら0を得るようなもの1[x∈leafl]を考える。
回帰木は、以下のように定義できる。所属している葉は1つしかないが、これを指示関数で表現しwlの重みを乗じている。
回帰木を構成するすべての葉について、すべてに重みを割り当てて帰ってくる値はそのうちの1つのxが行き着いた葉ということ。
1の総和は1つだけ1になるが、それについてRademacher変数を割り当てて考えてみる。つまり、以下のようになる。これらを成分としたRademacher変数のベクトルσがあるとする。つまり、重み
σ=∑i=1nσi1[x∈leafl] 回帰木のノルムについて、正則化の制限をする。q≤1,∣∣w∣∣q≤λである。
そして、h(x)のノード数(同じ葉の数でも、それに至るまでの条件分岐=ノードの数が違うかも)をmとする。これらを変数として、決定木の集合Hm,λ,qを定められる。
これからRademacher複雑度を計算していく。
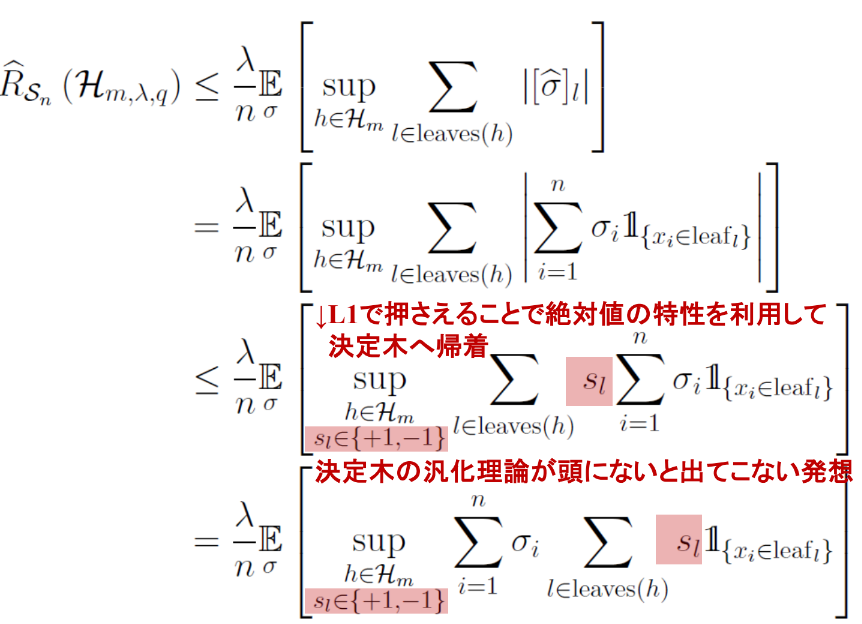
まず重みwとRademacher変数と枝を掛け合わせたσの内積に分解でき、次にHolderの不等式で内積をr,q,1/r+1/q=1のノルムに分解できる。
そのためにノルムの仮定を設けたのであり、次にrノルム単品はL1ノルムで抑えられる。
なぜL1ノルムで評価したのかというと、回帰木のRademacher複雑度の絶対値を外したい。絶対値を外したい=絶対値の外に−1,+1を取る変数を入れて、それのsupを取る事に当たる!(Rademacher変数も−1,+1を取るがあちらはランダム。これは恣意的に選べる。)
このようにslを導入できるには意味があって、最後の式変形のように総和の交換を行うことで、重みが恣意的に動かせるwである回帰木ではなく、重みが+1か-1であり、(1[]は1つだけ1となり他は0となる。1のところのslだけを出力する)決定木となる。
よって、これの集合を以下のようにすると、また式変形ができる。
このように、sl∈SnのRademacher複雑度に帰着できる。ノード数がmの二分決定木であると仮定する(そうじゃなくてlogに入れる都合上関係なさそう)と、そのような決定木の集合Bmの集合は有限である(前述のように、学習データが有限なので、意味がある決定木の数が有限ということ)
なので、Massartの有限仮説の補題から、抑えられる。
R^n(Bm)=n2log∣Bn∣ 回帰木を決定木に帰着したい、ということなのでL1ノルムで抑えたという形。
ノード数mの二分決定木とは何なのか
出来るだけきれいに分かれてる二分木である決定木のモデルを考える。
深さがDの時、葉の数は2Dであり、それに至るまでのノード数は1+2+4+⋯=2D−1である。
ノードの閾値をθ=0を固定し、各ノードの選択に使える特徴量の種類がd個であるとき、二分木全体のサイズは
∣Bm,0∣=dm⋅2m+1≤(d+2)2m+1 今は閾値が全部で統一しているが、閾値を自由に動かせる場合はどうか?無限に動かせるが、実質意味がある閾値はデータ点n個を分類するためにn+1個しかないので、以下のようにサイズを抑えられる。
∣Bm∣=(n+1)m⋅dm⋅2m+1