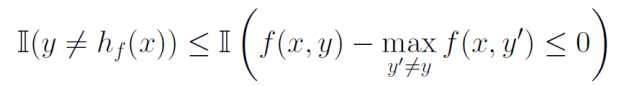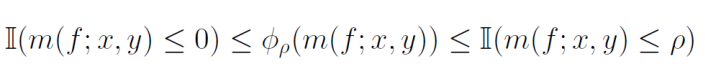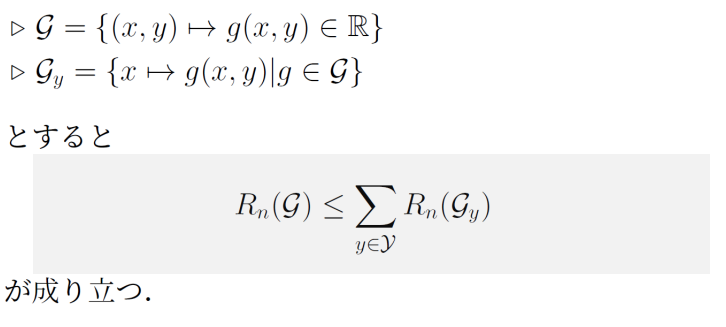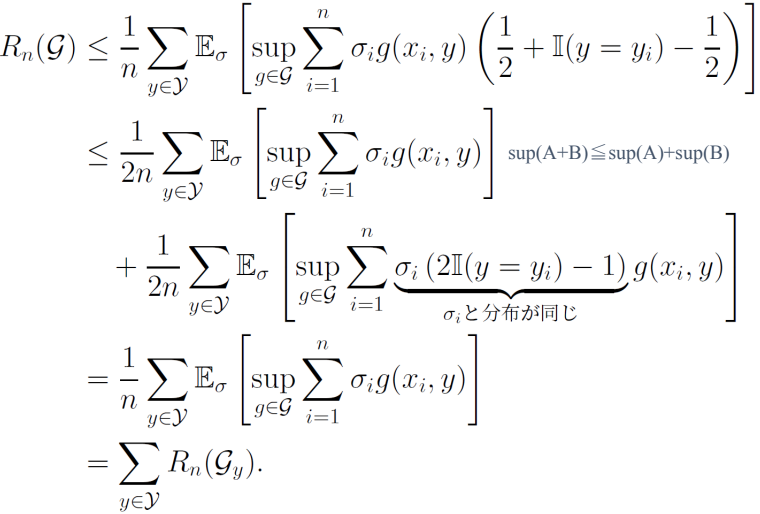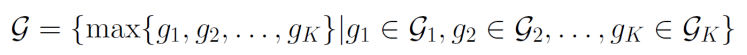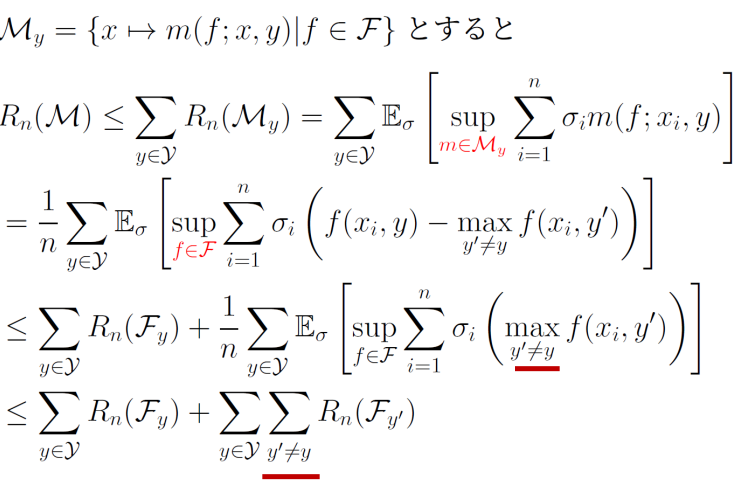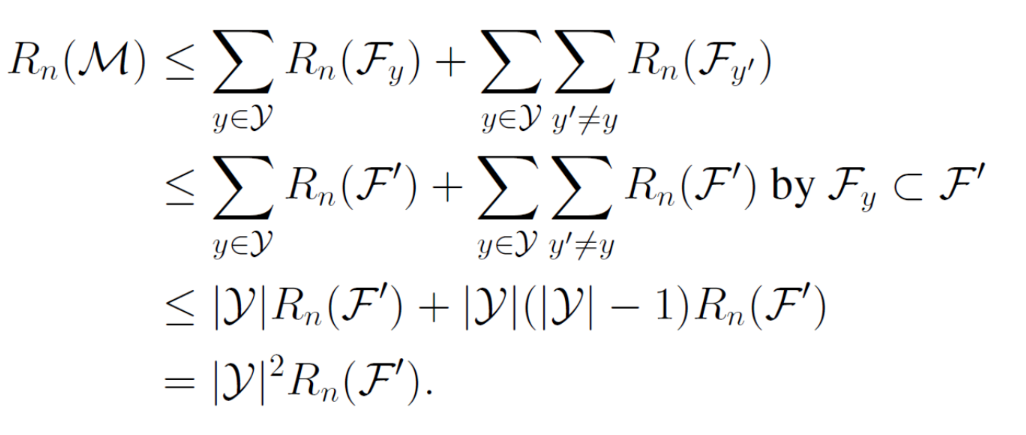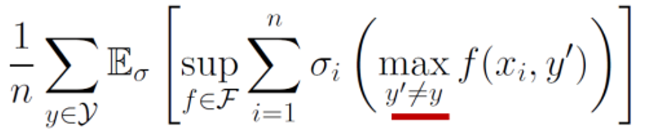前回はこちら。📄 (講義ノート)統計的機械学習第7回 。内容は以下の通り。
(講義ノート)統計的機械学習第7回 。内容は以下の通り。
多クラス分類
2クラス分類の問題問題設定(復習)
2クラスの定義は以下のようになっている。
そして、二値分類で、ヒンジ損失l((x,y),h)=max(0,1−yf(x))を使ったとき、リプシッツ定数は1であることから、損失関数のクラスのRademacher複雑度は以下のようになった。
Rn(L)≤Rn(F) 多クラス分類の問題設定
📄NNDL 第3章 線形学習 ここでも書いてある通り、出力はKクラスなので、{1,⋯.K}とする。関数fではクラスyにあたる重みベクトルwyを持ってきて、内積を得る。そして、仮説関数はすべてのクラスの間で計算した内積で最大の値をとる。
つまり、重みベクトルをすべてまとめるとm、W∈d×Kとなる。入力の次元はx∈Rdである。
多クラス分類のマージンは以下のように定義する。当該クラス以外のクラスの中で最も高いスコアを引く。これが正ならば当該クラスが判定結果であり、正ではないならば当該クラスではない。
そして、以下のように、ラベルが合わないというのは上の指示関数が成り立つ。
マージンが正ならば、正解を分類できて、負ならば誤った分類をしたということになる。これについて、マージンに対しての損失ϕρを考えることができ、以下のように経験的なマージン損失を計算もできる。
m(f;x,y)=f(x,y)−maxy′=yf(x,y′)R^S,p(h)=m1∑i=1mΦρ(m(f;xi,yi)) これらについて、ϕρ損失は以下のように抑えられる。傾きがρのRamp損失を階段関数で抑えている感じ。
証明の準備
そして、マージンの集合を以下のように定義する。ある識別器fについて、サンプルxiとラベルyの差=マージンを得るような関数の集合。
M={(x,y)→m(f;x,y)∣f∈F} また、次の関数の集合を定義する。通常のf:X×Y→Rだけではなく、任意の指定のクラスy′についてのスコアを得ることができるので、F′はw1,⋯,wK∈Rdの集合であると考えられる(与えられた正解ラベルyのみならず、任意のy′についてスコアを計算するにはこういう技巧が必要)。
F′={x→f(x,y′)∣f∈F,y′∈Y} 次にRademacher複雑度関連の準備をする。まず、以下のことが成り立つ。
- 上のものは、x,yを受け取ったらg(x,y)が返ってくるだけなので、識別器の仮説空間そのものである。
- 下のものは、クラスyを固定して、xだけを入力として受け取る。
つまり、すべてのクラスについて出力しうる仮説空間のRademacher複雑度は、特定のクラスに限ったスコアを出力する仮説の集合のRademacher複雑度をすべてのクラスについて足したもの以下である。
具体的な証明はここにある。
Rademacher複雑度関連の式変形では、とにかく∑iσiAの形を作り、しかもAがベルヌーイ分布に従うRademacher変数を与えられたとき、それに反応して半々の確率で正解なら1不正解なら-1の値をとるのが大事。
そして、ここでは識別器については指示関数で賢い変形をしている。
そして、先ほど作り出した1/2を加算、減算した部分は1/2の加算だけくくりだして、減算した部分は21[y=yi]−1になって、2クラス分類と同じように正解、不正解を+1, -1と値をとるようにすることができる。つまり、実は2つは同じものなので、最後に足し合わせたら、所要の形が出てきて示せる。
証明の準備2
次のように、G1,G2,⋯があるとする。この時、以下のようなことが成り立つ。Gは以下のように定義される。
Rn(G)≤∑i=1KRn(Gi) 一般的に、以下のようにmaxを書き換えられる。
max(g1,g2)=2g1+g2+2∣g1−g2∣ これを使うと、絶対値関数が1-リプシッツ連続であることから、以下のようになる。
絶対値とRademacher複雑度は相性がよく、Rademacher変数を乗じると符号にかかわらずランダム化される。そして、g1,g2の総和に対してsupをとると考えると、最大値をとるので符号がどちらも和なのが一番大きい。
これを再帰的に適用すれば、n個までの和まででも成り立つといえる。
多値マージンのRademacher複雑度の証明
m(f;x,y)=f(x,y)−maxy=y′f(x,y′)。該当クラス以外で最も確率が高いクラスとの差である。これを、以下のようにありうる仮説Fすべてに対して、ありうるデータからマージンを得る関数すべての集合。
M={(x,y)→m(f;x,y)∣f∈F} 次に、二値分類を多値分類に広げるため、以下のような仮説クラスを導く。これは二値分類から多値分類にただ広げているだけである。
F′={x→f(x,y′)∣f∈F,y′∈Y} この時、以下の式が成り立つ。実はこの上界はあまり良いものではないが・・・。
Rn(ϕρ∘M)=ρ1Rn(M)≤ρ∣Y∣2Rn(F′) ここから証明を始める。
まず、Mを各クラスごとのyの経験Rademacherの和で上から押さえられる。
そして、mはマージンの関数なので、これを展開するとsupm∈Myからsupf∈Fにすることができる。
そして、f(xi,y)の部分だけを単独でsupつけることで、それ自体がRademacher複雑度であるゆえに出すことができる。そして残った第二項について、以下の準備その2を使う。
Rn(G)≤∑i=1KRn(Gi) これによって、maxはunion boundのように抑えることができ、y′=yである全てのものに対しての総和となる。
次に、総和を取られているFy′についてだが、F′の定義は以下のようになっているため部分集合となっている。
F′={x→f(x,y′)∣f∈F,y′∈Y} よって、Fy′をF′に置き換えられる。
最後に、総和を∣Y∣で抑えていくことによって、確かに∣Y∣2となる。
二乗となっている理由として、Rn(F′)の和が二重の総和であった。これを改善する証明は以下の通り。
多クラス分類 上界改善版の証明
もともとの式は、1−δ以上の確率で以下の式が成り立っていた。
Rn(ϕρ∘M)=ρ1Rn(M)≤ρ∣Y∣2Rn(F′) これについて、改良版では1−δ以上の確率で以下の式が成り立つ。
Rn(ϕρ∘M)≤ρ4∣Y∣Rn(F′)+2mlog(1/δ) クラス数の1乗の上界になっている。
証明
m(f;x,y)から、新たなに以下のm(f;θ;x,y)を、ある定数θを用いて定義する。
m(f;θ;x,y)=miny′(f(x,y)−f(x,y′)+θ1[y′=y]) 通常の定義ではy′=yという制約であったが、これを取り払う代わりに「一致していたときにはθだけマージンに加算する」ということにする。これによって、選ばれたy′がyと等しいときは正解の時は固定でθの値となり(今までは第二の候補との差であった)、それ以外の時は通常のm(f;x,y)と同じようになる。
これについて、m(f;θ;x,y)≤m(f;x,y)が以下のように成り立つ。
m(f;θ;x,y)=miny′{h(x,y)−h(x,y′)+θ1[y′=y]}≤miny′=y{h(x,y)−h(x,y′)+θ1[y′=y]}=miny′=y{h(x,y)−h(x,y′)}=m(f;x,y) この新たに定義したものを使って、損失関数Φρ(⋅)を経由した経験損失との誤差は、同じ識別器に対しての経験誤差の評価なので、以下の式が1−δ以上の確率で成り立つ。仮説集合から得られたfについての計算。
H~={(x,y)→m(f;θ;x,y):f∈H}H~′={Φρ∘h:h∈H~}Φ^ρ(m(f;θ;x,y))−E[Φρ(m(f;θ;x,y))]≤2Rn(H~′)+2mlog(1/δ) 次に、Φρについて01損失で挟めることから、以下の等式が成り立つ。m(f;x,y)≥m(f;θ;x,y)であるので、0以下である確率は前者の方が小さくなる。
R(f)=E[1[m(f;x,y)≤0]]≤E[1[m(f;θ;x,y)≤0]]≤E[Φρ(m(f;θ;x,y))] これを使って、先ほどの集中不等式を書き直すと左辺を以下のようにすることができる。
Φ^ρ(m(f;θ;x,y))−R(f)≤2Rn(H~)+2mlog(1/δ) そしてここで、。θ=2ρであると固定してみる。この時、以下のようになる。y′が正解ではないときはm(f;x,y)と等しく、正解であるときもΦρはランプ損失であるので、ρより大きい値では常に0をとることから以下の式が成り立つ。
θ=ρで固定しないのは、将来の式変形で21[⋅]の形を作れるとやりやすいから…?
Φρ(m(f;2ρ;x,y))=Φρ(m(f;x,y)) (そのうえで、Talagrandの補題を使うことで、Φρは1/ρリプシッツ連続であるので、Rn(H~′)≤ρ1Rn(H~)が成り立ち、これで集中不等式を以下のように変形できる。
Φ^ρ(m(f;θ;x,y))−R(f)≤ρ2Rn(H~)+2mlog(1/δ) そして、Rn(H~)≤2∣Y∣Rn(F′)が成り立てば、証明は終わることになる。
F′={x→f(x,y′)∣f∈F,y′∈Y} これについては、すでに示されているRn(G)≤∑yRn(Gy)の証明と似た証明で示すことができる。
補題の証明
Rn(H~)=n1ES,σ[supf∑i=1nσi{f(xi,yi)−maxyf(xi,y)−2ρ1[y=yi]}]≤n1ES,σ[supf∑i=1nσif(xi,yi)]+n1ES,σ[supf∑i=1nσi{maxyf(xi,y)−2ρ1[y=yi]}] Rademacher複雑度の定義で展開して別々の項で考えることができる。
第一項はこの時、以下のようにYについての和をわざわざ作り出してみる。
この目的は、xi,yiの連動を消すことで、xiだけの関数にすればそれのRademacher複雑度が得られるからである。
すると、これは絶対値の外に出すことができる。
n1ES,σ[supf∑i=1nσif(xi,yi)]=n1ES,σ[supf∑i=1n∑y∈Yσif(xi,y)1[y=yi]]≤n1∑y∈YES,σ[supf∑i=1nσif(xi,y)1[y=yi]] ラベルについての指示関数とRademacher変数の積は相性がよく、ϵi=21[y=yi]−1とすれば、指示関数の0,1から−1,1と値をとるようになる。これを使って代入すると、以下のような形になる。
n1∑y∈YES,σ[supf∑i=1nσif(xi,y)21(ϵi+1)] そして、Rademacher変数と乗じたσif(xi,y)ϵi,σif(xi,y)の両方は、ϵiは+1,−1のみをとるので(yiと関係なく)、同じ分布であることがわかる。
よって、あとは外の総和を分解することで、第一項は∣Y∣Rn(F′)で上から押さえられる。
第二項については、第一項でσif(⋅)についてのRademacher複雑度を評価できたことから、すべてのyの総和を計算すれば、同様に∣Y∣Rn(F′)の上界を得られる。
第二項の残る−2ρ1[y=yi]については、指示関数が0の時は関係がなく、y=yiの時も1というk定数となるので、Rademacher変数を乗じたときの期待値は0となる。
このように、指示関数とRademacher変数は、
- f(⋅)の予測結果に関係ない場合は定数なので、Rademacher変数を乗じても期待値を取れば0。
- f(x,y)の予測結果と連動する場合、
よって、すべてを評価したとき、右辺は2∣Y∣Rn(F′)で抑えられて、当初の式を示せた。
当初の証明と何が違うか
この証明では、θを導入したマージンm(f;θ;x,y)を考えて、これを使ってm(f;x,y)を期待値で上から抑えている。そして、以下のように代わりのマージンのRademacher複雑度を考える。
H~={(x,y)→m(f;θ;x,y):f∈H} これのRademacher複雑度では、同様に支持関数を作り出すことで一次の∣Y∣で評価できた。
当初の証明では、以下のように別のMで評価していた。
M={(x,y)→m(f;x,y):f∈H} これについては、以下の部分のmaxは総和となったので、∣Y∣2のオーダーとなっていた。
これについて、改善版では、いきなり全体に対して∑y∈YをRn(G)≤∑i=1nRn(Gy)から適用しておらず、第一項では適用させているが、第二項の部分ではmaxをそのまま総和に展開させている。これが、オーダーの上界を根本的に改善させている理由である。