モデルや仮説の仮定
非常に基礎的なモデルから解析していく。
- X⊂Rdが学習データ
- Y={+1,−1}がラベルである二値分類。
- 損失関数はすべて01損失。つまり、損失関数というのは条件を満たさない確率そのものである。
仮説は2つの仮定の下で行う。
- 仮説空間Hは有限である。
- 期待損失∃h∗∈H,L(h∗)=0
有限仮説と実現可能性を仮定した汎化誤差
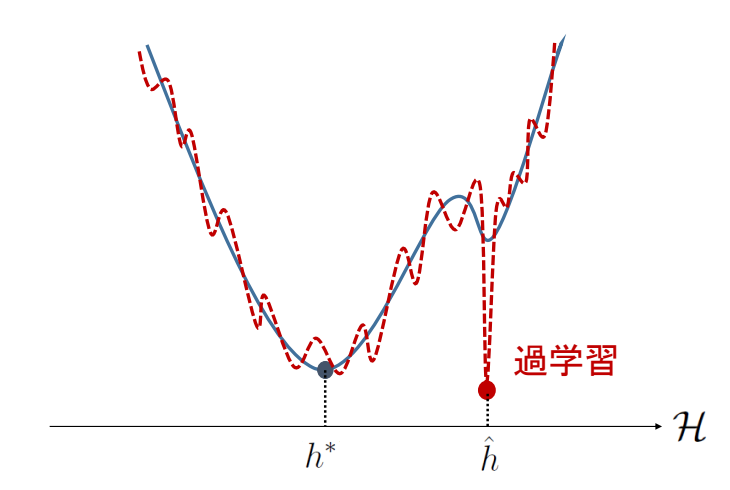
複数の最小化させるhは存在するので、一応集合ではある。だが、1つだけだと扱ってもまあよく見える。
前述の仮定の下(特に仮説空間が有限)で、h^∈argminh∈HL^n(h)つまり経験損失を最小化させるものをh^だとすると、少なくとも1−δ以上の確率で
L(h^)≤n1(log∣H∣+log(1/δ)) 仮説空間が複雑になればなるほど、確率が小さければなるほど上限が大きくなる。
証明
L(h∗)=0⇒L^n(h∗)=0。真の損失関数を0にするものが存在すれば、それは何個のサンプルについてであろうとも、経験損失は当然0にできる。なので、h∗⊆h^であるといえる。なので、h∗よりも広い集合h^について、すべてϵに収まるのは最低でも1−δ以上の確率であると示すという感じ。
まず、L(h)>ϵとなるような仮説空間H>ϵ⊆Hを考えることで、以下のように求めたい確率を同値変換できる。これで集合についての議論となった。
Pr[L(h^)>ϵ]=Pr[h^∈H>ϵ]Pr[h^∈H>ϵ]≤Pr[∃h∈H>ϵ:L^n(h)=0] 下から2つ目の式は、h^に限定しないようなhならばよいということで、右辺は左辺以上である。左辺の直接計算は難しいので、右辺で抑える。
そして、∃h,L(h)>ϵについて、以下が成り立つ。間違える率がϵ以上ということ。
P[L^n(h)=0]=Pr[h(x)=y]n≤(1−ϵ)n≤exp(−ϵn) すべて独立同分布からとっているので累乗にすることができ、毎回最高でも正解する確率は1−ϵである。そこから、1−x≤exp(−x)を使った。
そのうえ、Union Bound(集合の元についての討論なら、集合全体について合算して上限とする)を使える。
Pr[∃h∈H>ϵ:L^n(h)=0]≤∑h∈H>ϵPr[L^n(h)=0]≤∣H>ϵ∣exp(−ϵn) ここでは、集合の元すべてで抑えている。
したがって、ここまでの議論をまとめると以下のようになる。
Pr[h^∈H>ϵ]≤Pr[∃h∈H>ϵ:L^n(h)=0]≤∑h∈H>ϵPr[L^n(h)=0]≤∣H>ϵ∣exp(−ϵn)≤∣H∣exp(−ϵn)=δ 最後にδを定義してあれば、証明したいものが得られる。
1−Pr[L(h^)>ϵ]=Pr[L(h^)≤ϵ]L(h^)≤ϵ=n1(log∣H∣+log(1/δ)) Q.E.D.
一様収束(Uniform Convergence)と各点収束
これは一様収束。まずN0を定めて、そこからすべてのXの元がN0基準とした収束速度だと保証する。N0はϵにのみ依存する。
∀ϵ>0,∃N0∈N,∀x∈X:[n≥N0⇒∣fn(x)−f(x)∣≤ϵ] 下は各点収束。N0はϵ,xに依存する。
∀ϵ>0,∀x∈X,∃N0∈N:[n≥N0⇒∣fn(x)−f(x)∣≤ϵ] すべての元がそれぞれ収束するとしても、同じ基準N0で収束しないといけないルールはない。
一様収束のうれしい性質
- 一様収束する→各点収束する
- 一様収束する⇔limn→∞supx∈X∣fn(x)−f(x)∣→0
- 連続関数の一様収束極限も連続関数。
- fnがfに一様収束するときに限り、微分積分と和を交換できる=項別微積分ができる
一様収束がなぜ機械学習で重要か
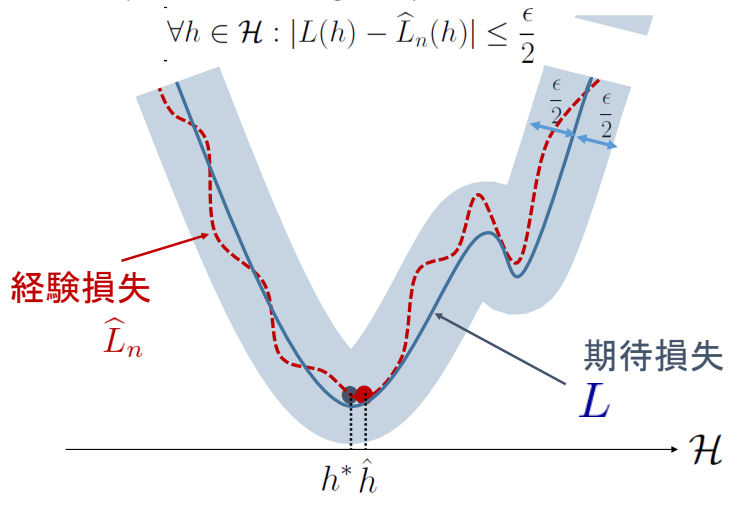
定義からして、一様収束するなら絶対に同じ収束速度で、どの仮説であってもϵ/2に収まるということ。
このように、サンプルから得られた経験損失で過学習は起きることがあるが望ましくない。各点収束では、過学習の点の収束速度が他と違うということになる。だから一様収束で議論するべきである。
経験損失の誤差を一様収束でどのように抑えられるか
具体的に式で定義すると、以下のようになる。
Pr[L(h^)−L(h∗)>ϵ]≤Pr[suph∈H∣L(h)−L^n(h)∣>2ϵ] 左辺にはh∗があるが右辺にはない。∀h∈Hの中で一番広がる部分がどこか?で言い換えられる。→h∗が具体的になんであるのかを見なくていい!また、h^が損失関数Lnによって決定されている関係上、Lnは独立な変数として扱えないのも面倒だが、右辺ではその問題を無視できる。
では、これが正しいのを証明する。
証明
suph∈H∣L(h)−L^n(h)∣≤ϵ/2が成り立つならば、
- L(h^)−L^n(h^)はh∈Hなので、L(h^)−L^n(h^)≤ϵ/2が成り立つ。
- L^n(h∗)−L(h∗)≤ϵ/2も同様に得られる。
よって、以下のようになる。与えられた条件は理想損失と経験損失の差を限定させているが、何とか理想損失だけで差を出したい。ここでは、
- Lから経験損失のL^n2つ作り出す。この2つは、既存のLとCouplingして、条件を使えるようにする。
- 作り出した部分L^n(h∗)−L^n(h^)≥0は正であるという性質が好都合。不等式の符号がそろう。
L(h^)−L(h∗)≤{L(h^)−L^n(h^)}+{L^n(h∗)−L(h∗)}≤ϵ よって、確率の中で改めて考えると、
Pr[suph∈H∣L(h)−L^n(h)∣≤2ϵ]≤Pr[L(h^)−L(h∗)≤ϵ]Pr[suph∈H∣L(h)−L^n(h)∣>2ϵ]≥Pr[L(h^)−L(h∗)>ϵ] このように計算ができる。Q.E.D.
結局、一定の範囲内に抑えられるというのがやりやすいので変換してやっているだけ。