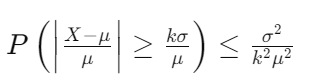前回は📄 (講義ノート)乱択アルゴリズム第5回
(講義ノート)乱択アルゴリズム第5回
グラフの枝数の推定
巨大すぎるグラフのは枝の数を推定することすら難しい。これを∣V∣がわかっている状態で枝の数∣E∣を推定したい。
ただし、道具として以下の質問に答えられる、絶対に正しい機械=オラクルがある。以下で言うランダムは、一様分布に従ってサンプリングという意味。
- ランダムな頂点を教えてくれる。
- 指定の頂点の次数を教えてくれる。
- 指定の頂点のランダムな隣接頂点を教えてくれる。
平均次数をdˉ=∑vdv/nと計算できるが、これは全部計算するともちろん2∣E∣/∣V∣となる。このうまいこと平均次数を使いたい。
しかし、このまま仮定がなくd1,⋯がランダムならば何もできない。
例えば、次数が正であるので、分散をまず見てみる。Xiは次数を表す確率変数。
V[X]=E[X2]−E[X]2=n∑vdv2−dˉ2 何回サンプルすればいいのか、というのを考えたい。そこで∣E∣のオーダーを落としたうえで推定できないと困る。
チェビシェフの不等式Pr[∣X−E[X]∣≥kσ]≤k21の別の形である以下の式?を使うと、
右辺はさらにV[X]/E[X]2以下とkを外した形にできる。これを代入して計算すると、∣E∣1d2∑vdv2となるが、これはΩ(∣E∣)なので、よくない。
悪さをしているのは外れ値で、分散が大きいとどうにもならない。何とか推定する頂点の分散を小さくしたい…!
じゃあ分散を大きくするような外れ値はそもそも推定しなければいい。気持ちとしては、次数が大きすぎる頂点の次数を推定せず、小さいものをちゃんと推定する。外れ値を取り除くと言える。
まず、diを降順にソートする。この補題は、次数が多いk個の頂点の次数の和は、次数が低いものの総和と何かで抑えられるというもの。
k個の次数の多い頂点から出ている辺は、自分の中でクリークを作るのをのぞくとk個以外の頂点へつながるし、それは∑i>kdiで評価できる。なので、右辺にはクリークを作る場合と考えたkC2を入れれば上界となる。
∀k∈ϵ[n],∑i≤kdi≤∑i>kdi+kC2 これを使うことで、以下のようにできる。
dˉ=∣E∣∑i≤kdi+∣E∣∑i>kdi∣E∣1∑i>kdi≤dˉ≤n2∑i>kdi+n1kC2 ここで、k=ϵndˉと選ぶと、エラーϵdˉとなるらしい。
ここで、Y=∑j≤tXjの解析を考える。
アルゴリズム
for i from 1 to t = O(\sqrt{n} / epsilon^2):
uを頂点集合Vからランダムにサンプリング。