
https://arxiv.org/abs/1611.01586
Journal Paperなので非常に長い。
Introduction
PositiveとUnlabeledは以下の通り。
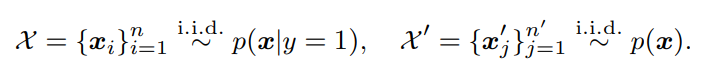
そして、実際には知らないが、Negativeのデータの分布というものがあり、全体の分布はClass PriorというPositiveのものの割合を使って、以下の混合分布のようになる。
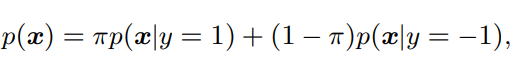
この論文では、PositiveのデータセットとUnlabeledのデータセットのみを使って、Class Priorのを推定するのが目標。
前提として、Positiveの密度分布関数とNegativeの密度分布関数がわかっていれば、図(a)のように理論上峰の高さから、Class Priorを計算することはできる。その距離は一般的にはKLダイバージェンスやf-ダイバージェンスを用いる。
一方、図(b)のように、片方しかわからない場合は、最高峰の比較ができないので、推定が難しい。(Positiveデータしかないので計算自体はできるが、正規化とかいろいろ丁寧にやらないと…)
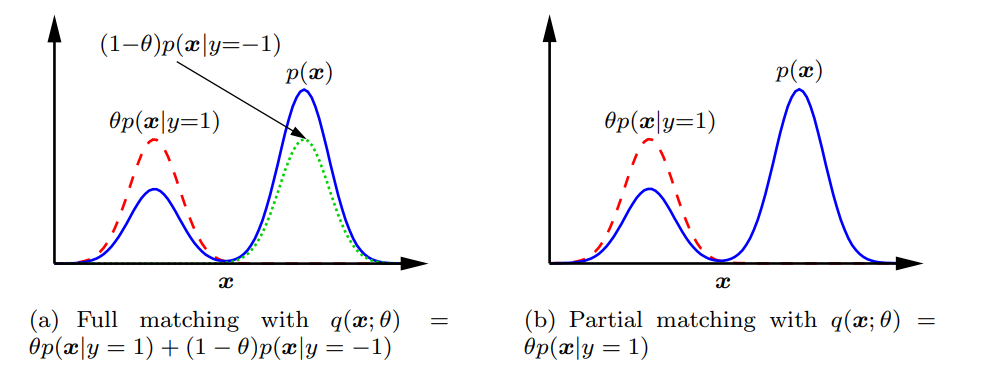
こういう前提に立って、KLダイバージェンス、Pearsonダイバージェンス、L2距離による最小化、MMDが先行研究としてあった。しかし、PositiveやNegative両方のクラスからのLabeled Samplesが必要である。
ここで、図(b)のPartial Matchingの提案は2014に提案されている。以下のDivergenceを最小化させる。(がClass Priorである)
しかし、この論文では既存のすべての手法はClass Priorを過大評価していたことを示す。そして、f-divergenceに適切なペナルティを科すことで、正しく推定できることも示す。L1距離によるペナルティから着想を得ていそう。
提案手法
先行研究はなぜ過大評価してしまうのか
f-divergenceにおいて、で最小値を持つを考える。そして微分可能であり、の時はで、の時だけとなる。この条件はPearson, KL Divergenceのいずれも満たす。
次に、f-divergenceの計算をする式を、で微分することで極小値をとる点を求めていく。つまり、以下の式が0となる。
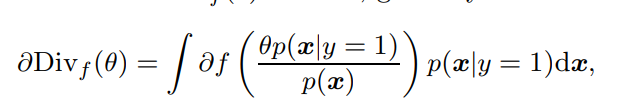
しかし、仮定により以下のような条件付確率と書くことができるので、に入れる値はであり、先ほどの仮定により微分は負かゼロとなる。
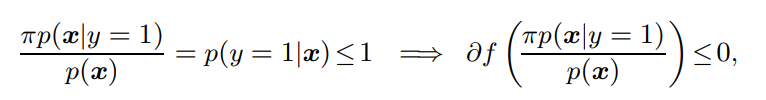
このことを踏まえて、を計算する。積分を計算するとき、の領域と、の領域に分けて積分する。
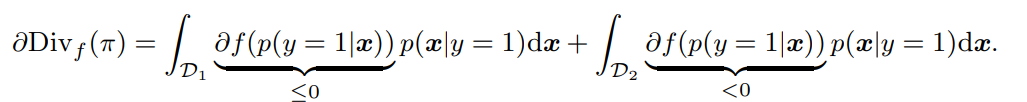
これの極小値を求める、つまりこの式が0をとるときは、の時だけ。これは非現実的な仮定。それ以外の時は、明らかに上の導関数は負の値をとる。よって、Divergenceの最適化をするならで値をとることになるが、確率の性質上これは正しくないので、は過大評価されている。
f-divergenceによるペナルティがあるPartial Distribution Matching(提案手法)
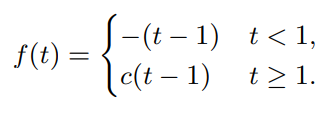
f-divergenceの関数を次のように改造する。は定数であり、の時はただのL1-Divergenceである。このように調整を施すことで、となり、ただ最適化すればいいだけというのが目標である。
まず、がでは成り立つので、以下のように書き直せる。
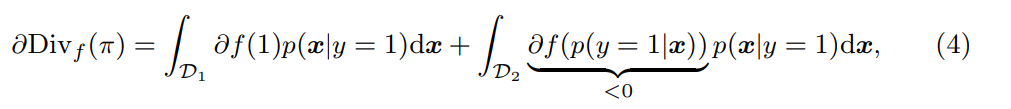
は基本で微分不可能であるので、劣微分を考える。
劣微分とは、微分不可能な点において、接線を引くときにとれる傾きの閉区間を微分係数として扱うというもの。基本的に凸関数にのみ使われる概念。
計算すると、劣微分である。よって、劣微分によって、における微分係数は以下の区間となる。
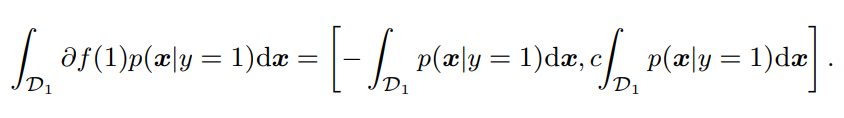
そして、の区間で定めたはとなるので、以下のように書き換えられる。
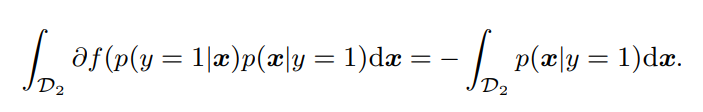
ここで、f-divergenceで導関数が0となるには、があらわす区間の中に0が含まれる必要がある。つまり以下の条件。
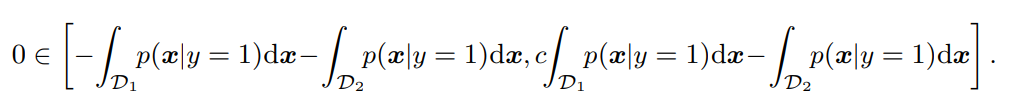
この区間の右辺が0未満だと持たないということになる。
ここで解決法として、と提案している。
これでは単純には等倍としているだけである簡単な写像である。もちろん、本来の関数を使ったf-divergence荷重適用できる。以下のようにすればいい。
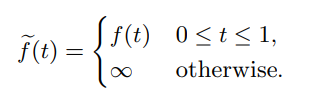
このように、提案したによって、Class Priorの過大評価を防げるというもの。
ペナルティつきf-divergenceの直接な評価
Fenchelの双対性定理について解説(GPT先生)
凸関数と凸集合
- 凸関数: 関数 が凸関数であるとは、任意の に対して次の不等式を満たすことを言います
- 凸集合: 集合 が凸集合であるとは、任意の に対して、点 が に属することを言います。
凸共役(Legendre-Fenchel変換)
- 関数 の凸共役 は次のように定義されます:
ここで、 は と の内積を表します。
Fenchelの双対性定理
Fenchelの双対性定理は、以下の最適化問題の対について述べています。
主問題(Primal Problem)
双対問題(Dual Problem)
ここで、 と はそれぞれ と 上の凸関数、 は から への線形写像(行列)、そして と はそれぞれ と の凸共役です。
定理の内容
Fenchelの双対性定理は次のように述べられます:
- 弱双対性: 任意の と に対して、
- 強双対性: もし と が下半連続な凸関数であり、さらにある点 と が存在して、以下の条件を満たすなら、
これを強双対性と呼びます。すなわち、主問題の最適解と双対問題の最適解が一致するということです。
ここでは、スカラーであるので凸共役は単純な積である。つまり、凸共役はである。右辺はsupなので、不等式として以下のように書き換えられる。
そしてここに以下のように代入する。はという新たな関数で書けるとする。
代入したのち、両辺にを乗じてから、積分をすると左辺はf-divergenceとなる。右辺について、同様に積分するだけではなく、任意のについて成り立つので、最大のものを選ぼう、ということ。
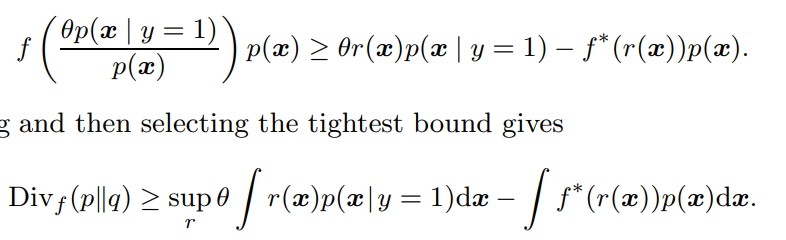
この式について、もしは線形関数である場合、経験的な式に直す(確率との積分が総和になる)と、最適化はやさしい。なぜならば、右辺はも線形関数で凸関数、も凸関数であるので、凸最適化しやすいから。
ペナルティ付きL1距離推測
色々書いてあるが、相対で考えると凸最適化できるいい性質を持っている!を力説している。
Theoretical Analysis
省略します…