


上が参考資料
Attentionとは何か
まず、一連のデータを格納したデータベースがあるとする。
- で表される、データのKey、ラベルを表すもの。
- で表される、データの本体。
このペアが大量にDBにあるとする。
ここで新たに、問い合わせれのクエリとして、 が与えられるとする。完全に が一致する必要はないが、一致するデータほど色濃くクエリの答えの答えとして帰ってくるようにしたい。
この操作をAttentionとである。
個のクエリがあり、 個のペアがDBにあるとする。
- として、 個のクエリが与えられる。各行が1つ1つのQueryとなっている。
- として、 個のDBのkey-valueがある。各行が1つ1つのKeyとなっている。
- として、 個のDBのkey-valueがある。各行が1つ1つのValueとなり、 の 行目のKeyは の 行目のValueに相当する。
この時、Attentionの1つのうやり方として、以下のようにあらわせる。
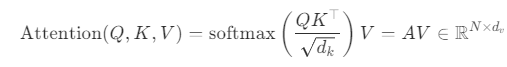
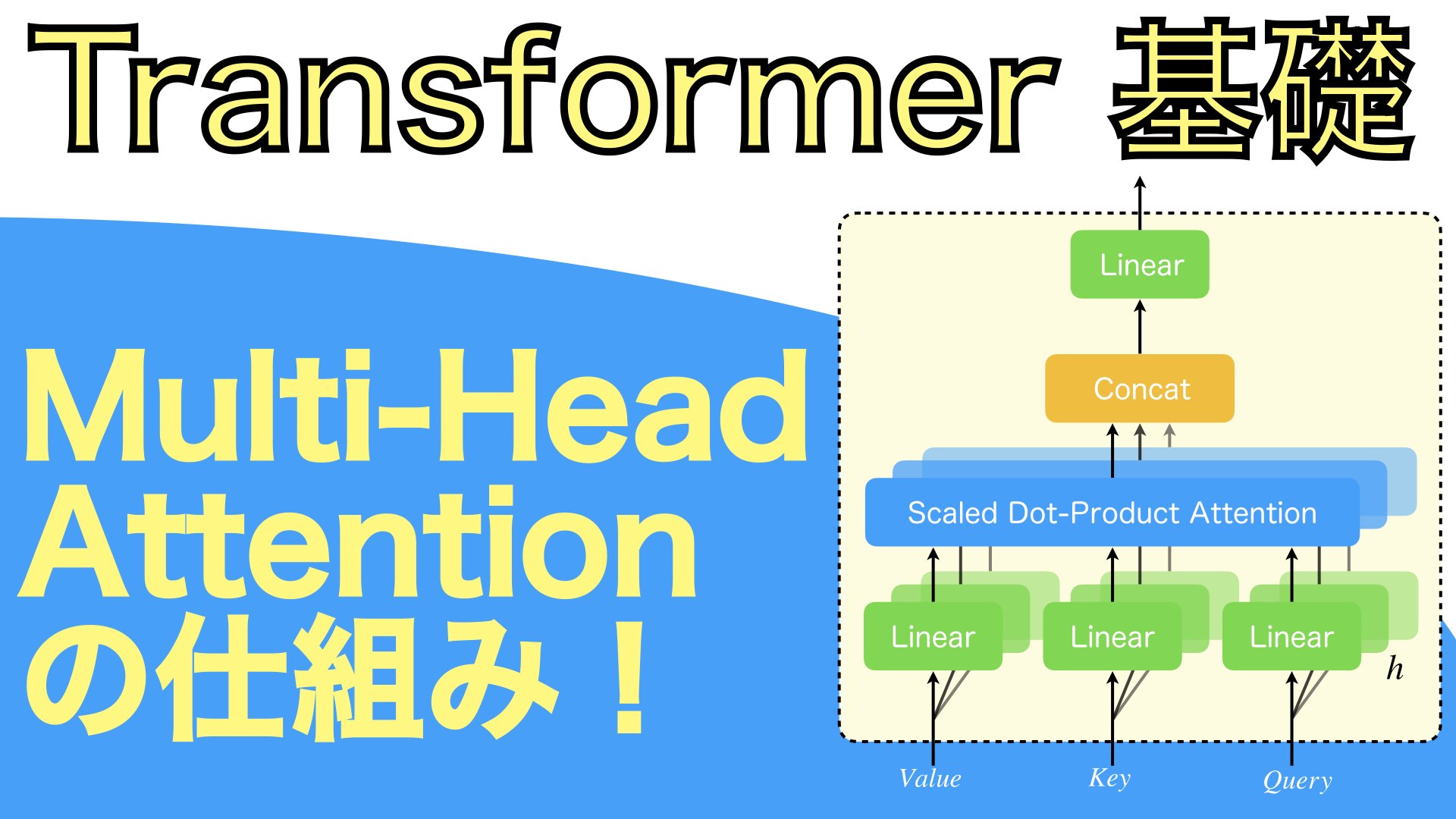
では、QueryとKey同士の内積を求めているといえる。演算結果は の行列であり、 成分は 番目のQueryと 番目のKeyの内積。合致度が高ければ、この内積が大きくなるというものらしい。
それを次元数の平方根 で割って正規化している。
そして、softmaxは横向き、つまり の行に対して、softmax。これで、各Keyに対して、このQueryに対してどれほどの重みをもたせるのかを決定している。
そしてこのような操作を施す一連の流れは、 というAttention行列を作っているといえる。Attention行列の中で が高い値をとることは、 番目のQueryと 番目のKeyは合致しているということであり、その重みとみなせる値を と掛け合わせた結果、 のサイズのデータの問い合わせ結果が得られる、という仕組みである。
Attention is all you needってなんだよ
今ままではRNNとAttentionを同時に使用して、NLPのタスクを使っていた。しかし、RNNは設計の仕組み上並列計算ができないので、計算コストが高いことが難点。
そしたら、Transformerでは、Self-Attentionを用いることができるならば、RNNはいらん!というのが主張だ。
Single-Head-Attentionとは
まず、Single-Head-Attentionについて説明。上のAttentionでは学習パラメタが存在せずすべて固定されているといえる。
これに対して、Value, Key, Queryの前にそれぞれ線形層を1つ挟み込むことによって、(線形に限るが)学習の意味があるようにすることができる。これがSingle-Head-Attentionである。
Multi-Head-Attention
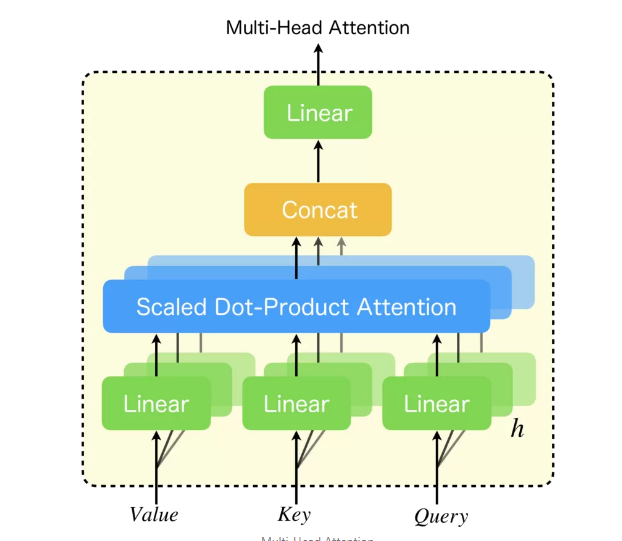
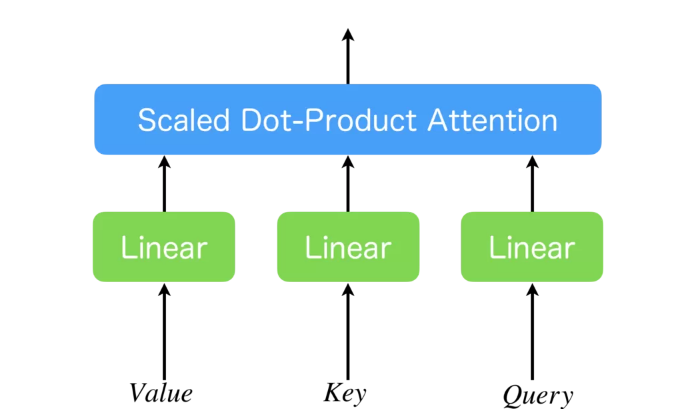
このSingle-Head-Attentionを同時に並列に数本並び、同時に学習をさせることができる。複数並べることで、
- 複数の線形層が(並列に)存在するので、一義ではない意味などでも複数個のheadでattentionすることで、とらえやすい。
- 同時に並列して独立して計算できる。
複数本で行うというのは、具体的には以下の手順のようになる。元のQueryやKeyは512次元ある(Valueは512次元である必要はないです)と仮定する。
- 512次元のQueryやkeyのものをhead本コピーする。
- 各headについて、いい感じの線形変換(これも学習でパラメタが更新される)を行い、64次元(例)のものにする。
- ここでの線形変換はSingle-Head-Attentionの緑のLinearの部分も兼ねることになる。
- それぞれAttentionする。
- その結果をContactで結合する。結合する も学習される。
複数個のheadで計算したら、最後にContactの部分で結合しないといけない。具体的には、以下の式となる。
このように各headは結合される。
なお、いずれの場合も、このままのAttentionでは各トークンの位置関係をとらえることができないし、多義語などについても一義な表現として扱われてしまう。これを防ぐために、Transformerアーキテクチャではなんとか位置情報も埋め込みたいということになる。
Encoder-Decoderモデルとはなんだ
Encoderという、サンプル から、内部の表現ベクトル に変換するものがある。その表現ベクトル を受けて、出力 を出力していくというモデル。
誤差逆伝播するときにはもちろんDecoder → 内部表現 → Encoder の順序で更新していく。
意図的に内部表現を一度生成させることでの利点は以下の通り。
- 異なる長さのシーケンスの処理をしやすい。
- 強制的に情報の圧縮をさせることができ、サイズを落とせたりする。
- モジュール性がある。Encoderだけパラメタの学習を止めることもできる。
欠点としては以下の通り。
- 内部表現に落とし込むことになるので、どうしても表現力は落ちてしまう。
- Encoder-Decoderのそのままでは長期的な依存関係をうまくとらえられない
- これをSelf-Attentionと場所情報の盛り込みでうまくやったのがTransformerアーキテクチャ。
- 並列処理がほぼできない。Encoder → 内部表現 → Decoderなのでシステム上さすがにね、無理。
TransformerでのEncoder-Decoder
Encoder, DecoderとAttentionだけでやっているのがTransformer。Decoderでは、毎回以下のように推論している。
- 今までのDecoderの出力の列を入力する。
- 位置情報の埋め込みを行う。
- Self-Attentionを行う。
- Encoderからの埋め込みの情報をもとに、Cross-Attentionを行う。
- つまり、AttentionはSelfとCrossで2回行われる。
- 最後に出力したいトークンを出力して終わる。
訓練をするときは、
- Input: [START] → Output: [START] This
- Input: [START] This → Output: [START] This is
- Input : [START] This is → Output: [START] This is a
- Input: [START] This is a → Output: [START] This is a pen
- Input: [START] This is a pen → Output: [START] This is a pen [END]
このような出力したトークンについてそれぞれ誤差逆伝播を行って、訓練をしなければならない。この時、同時並行しながら行ってよいのであるが、それをするためには、「Input: [START] This → Output: [START] This is 」の場合、「a pen [END]」のトークンの情報を使ってはいけない。そのためには、Masked Multi-Head Attentionをするといって、DecoderでのSelf-Attentionの学習には使用してはいけないところのデータにマスクをかけつつ、同時に学習を進めていく。