
https://arxiv.org/abs/2402.05932
Introduction
運転は地域によって規則が違ったりする。同じ国でも違ったりすることがある(アメリカの一部の州では赤信号でも右折可能)
この論文はLarge Language Driving Assistant(LLaDA)というものを開発し、それを実現しようとした。提案手法は以下の3ステップである。
- 既存の手法を使い、実行可能な運転ポリシーを生成する。
- 自然言語で記述された予期しない状況に遭遇したら、今の状況と関係する交通規則を抽出するTraffic Rule Extractor(TRE)を得る。
- TREの出力と1で得たもともとの運転ポリシーを組み合わせて、LLMに入れて最終的な結果を出す。
Related Works
交通規則の埋め込み
論理形式のルールベースで埋め込むことは膨大な入力が必要で難しい。交通ルール自体は自然言語であることを利用して、機械学習で埋め込みを計算した方が良い(書いてない部分は常識でなんとか補ってもらう)
LLMはロボットなどを動かす指示としても有効
LLMを使って、交通規則と当初の運転ポリシーを組み合わせたものを使いたいね。
自動運転におけるLLM
LLMを使って、運転に起こるレアな状況の常識的判断を行ってもらう。よくあるのはLLMを運転用にFine-tuningしたりするが、今回の研究はLLMは常識的判断だけを担当するようで、重みを更新せずに凍結して使う。
提案手法
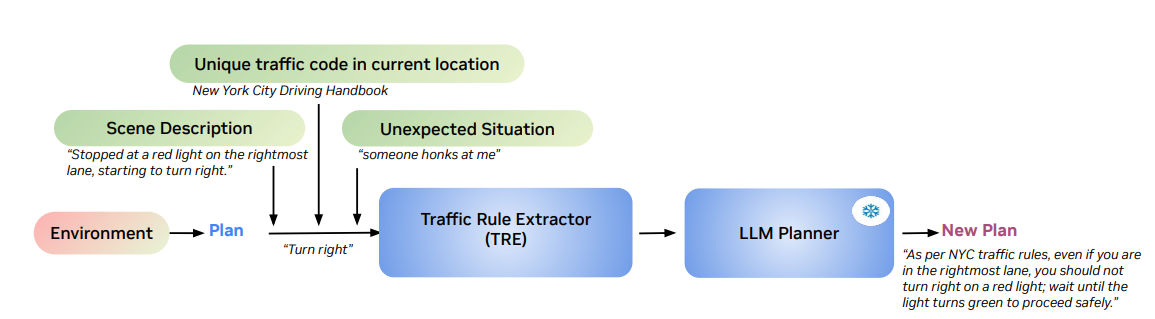
TREは以下の4つの入力を受け取り、妥当な表現をLLMに出してもらう。このTREを訓練する。
- 環境から生成された当初の運転ポリシー
- 今いる地域の運転規則
- 現在の自分が置かれている状況
- 予測してなかった追加で発生した状況(なんか警笛鳴らされたが…?)
具体的なアーキテクチャ
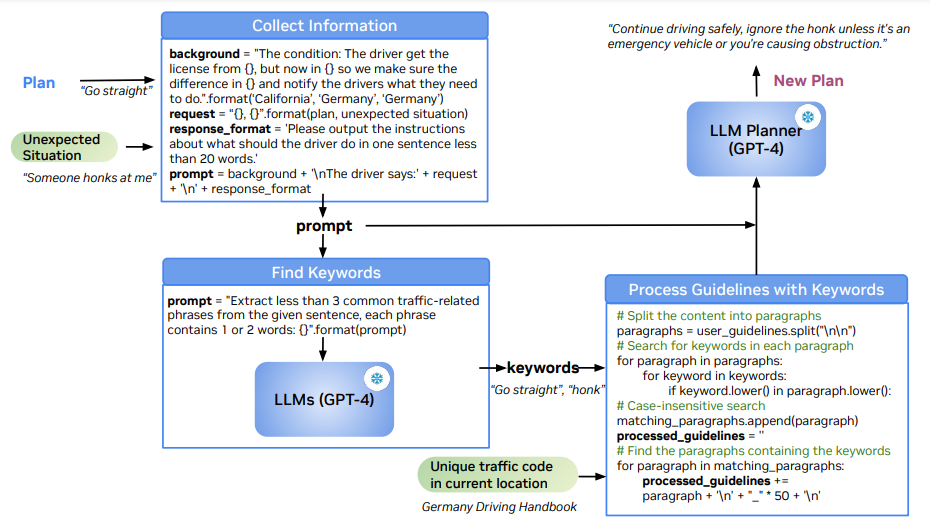
- 「当初のPlan」と「予測してなかった追加で発生した状況」を使って、文字のPromptを生成する。
- 1で得た文字のPromptからキーワードを抽出し、交通規則の中でそのキーワードを含むものだけを「関係ありそうな交通規則」として使う。
- 2で得たものと1で得たPromptを組み合わせて、LLM Plannerに新しい運転ポリシーを作ってもらう。
というわけで一切訓練しないです。Prompt Engineeringです。
LLaDAの応用
- 旅行者への交通規則のアシスタント
- 旅行者は旅行先で交通事故に遭いやすいし、何がわからないが不明ならば聞くのも難しい。それを補助していく。
- 自動運転への補助
- 車は物理的に地域を移動するので、このように地域差を補正した運転は絶対に必要。
実験
カリフォルニアで運転免許を取ったドライバーを想定する。
LLaDAは例えばシンガポールでの運転を試してみた。他にも自立装甲車のセンサーの情報を持つデータセットのNuscenesと自立運転のための世界初の閉ループ(外の環境を受け取って自分のこれからの動きを調整する)ベンチマークのNuplanも試したが、自分の動きについては不十分なラベルしか提供されてない。なので、ランダムなビデオの上でもLLaDAを試したら普通にうまく行った。
評価基準は計画された軌跡と実際の軌跡のL2誤差(メートル単位)と衝突率である。
結果はSOTAだった。理由としては、GPT-4はコンテキストや複雑なPrompt Tuningがなければ詳細な指示を提供できないからであり、LLaDAはそれにあたるものを提供したと言える。
ここではGPT-4を使っているが、さらにVisionの入力を受け取るGPT-4Vにすることで更なる応用ができる。
Future Works
提案手法の限界としては
- LLMで複数回推論するので、時間がかかる。Closed Loopのものでは推論が間に合わない(推論結果出る前に車が先に動くので)
- シーンの説明の言語の質に強くLLaDAは依存する。なのでGPT-4Vのように画像が取り込めるようになったとしても、言語による説明に強く依存する。
これからは、予測していないようなレアな事項のタスクについても対応できるようにしたい。