
https://dl.acm.org/doi/abs/10.14778/3611479.3611511
Introduction
Webページなどは情報を高い質でまとめたものであるので、その構造化された情報から抜き出すのは重要である。だが、構造はお互いに違うので簡単にまとまって取り扱えない。(ショッピングをWebでやるとき、食品サイトや電機サイトで構造がお互いに違う場合とか これらで簡単にコーパスを作れない)
既存の手法は人間がWebpageの構造を見て、wrapperを作ってスクレイピング。これでは見たことのないWebページには対応できない。
これに対して、弱教師付き学習のアプローチを考えた。
先行研究では、外部KBを使った、距離監察?をやっている。ただしこれは詳しくないor出現頻度が低いものがあるときにうまくいかないらしい。これを解決するために、転移可能なモデルを開発した。ちゃんとラベル付けされたデータで事前学習させた後、特定の分野へfine-tuningをする。でも、それラベルコスト高いよね?自己教師あり学習の手法はあるが、やはりラベル付けコストが高いらしい(特定の分野へのfine-tuningで専門家によるアノテーションがそれなりに必要ってことかな?)。
この論文は
- どのようにシード(事前学習で使うデータ)とターゲット(特定の分野へ特化させる学習データ)の両方におけるアノテーションコストを減らせるか。
- 1のためのモデルの性能にできるだけ影響を及ぼさないようにできるか?
最近では、Teacher Modelで人間でラベル付けされた例を使ってコーパスを訓練し、そこからコーパスのUnlabeledにラベルを付けて行く。人間でラベル付けされた例と自動でラベル付けされた例の両方でStudent Modelは訓練されていく。そしてTeacher ModelをStudent Modelで初期化して再び。お互い収束するまでやる。(sample-selection methodで何度も収束するまで繰り返すやつやないか!) だけどお約束の通りこのモデルはNoisyに弱い。
この研究の貢献
- 自己教師あり学習で着けていくラベルの質をよくするための自己教師あり学習モデルを開発した。
- Noisyな自動ラベル付けされたラベルであっても、識別器の品質が低下しないように尽力した。
Background
Web Pageの情報抽出
(各ジャンルとしての)WebPageにはそれぞれで(具体的な1つ1つのものを示す)Detail Pagesがあるとする。このDetail Pagesから情報を抽出したいのだ。多クラス分類だとみなせるらしい(謎)。たぶん、複数のオブジェクトの中から中抽出すべき項目は何かを選んでいる。
Self-Training Web-Extraction Models
先ほど言っていたTeacher Model, Student Modelの話
- すでにあるラベル付けされたものでTeacher Modelを訓練。
- Teacher Modelで、いくつかのUnlabeledを選び、それをAnnotationしていく。
- 2でAnnotationしたデータも含めて、Student Modelを(パラメタをTeacher Modelのものにして)訓練しなおす。
学習によるパラメタの更新は普通に確率的勾配降下法です。
手法
Supplementary Supervision Source
各カテゴリごとにそれぞれ何かしらの典型構造を持つとしている。その典型構造から外れてしまうWebページから集めたデータはNoisyなものになる。
距離監督という、すでにDBなどで子いう増加されている情報を用いてのラベル自動生成テクがある。DBに「AさんがB社の社長」という知識があるのならば、文中に「社長」というのが出てきたら、知識に結び付けてラベル付けを行うように。
Webページの構成は以下のような順序で行われるとする。
- 情報を含んだお互いの抽象関係があるとする。
- 抽象関係(DBみたいなものと考えておく)から特定の行たちを抽出する。=Selection
- 次に、2から特定の列たちを抽出する。=Projection
- 今のWebサイト特有のページレベルのノイズを3に加える。余分な、誤った属性値を追加のように。
- 4を具体的なHTMLコードとしてレンダリングする。
これを逆にたどっていきたい。
そして、情報抽出において、2つの重要なコンセプトがある。
ページレベルでの一貫性
特定のWebPage以下の詳細なページすべてから情報を抽出するとき、何かしらの一貫する規則をもって抽出するということ。ページと着目するようなノード、抽出する属性を与えて抽出させる感じだ。
重複する属性
異なるWebSite間の重複する属性を持つ詳細ページを整合させることによって、WebSite特有の関係の推測につなげることができる。
この2つの重要な性質がある。
Uncertainty-Aware Training
自己教師あり学習でつけたラベルで学習したときに、noisyなものが入ってドメインシフトがおこってしまうことがままある。これを防ぐため、Uncertainty-Aware Trainingというのをやる。以下のことをする。
Adaptive re-weighting
各例の重みを変える。具体的には、重みを にすること。Noisyな例ほど重みを軽くする感じだ。
人間のラベル付けされた例の重みは1。自動でラベル付けされたものは、そのWebSiteのStudent ModelにおけるAccuracyにする。
しかし、1つも人間のラベル付けがなければ上のプロセスは訓練しようがない。この時はJaccard Similarity Scoreを使って計算する(Bag-of-Wordsだとみなしてやるらしい) 謎。
Noise-aware loss
Noise-aware Lossというロスを設計する。
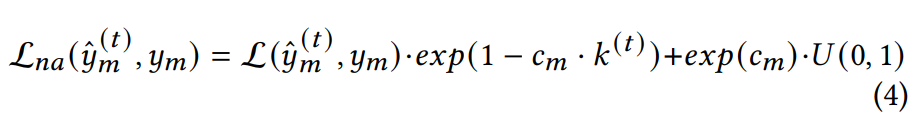
は0から1の一様分布からのランダムの値。二項目は正則化項。損失はクロスエントロピー損失。 は分布のシフトをペナルティするための項。 は以下のようにアップデートする。 は0以上の定数。
End-to-End Workflow
全体の流れは以下の通り。

解説をしていく。
- は人間によってラベル付けされたデータ。 はUnlabeledのデータ。
- イテレーションは 回。
- 毎回新たにラベルをつけるのは 個。
- Teacher Model、Student Modelの訓練用のコーパスはそれぞれ とする。(まだ訓練はしていない)。それぞれ重みは1。
- T回のイテレーションで以下を繰り返す。
- Teacher Modelを訓練する。
- から、変更を許すことなく(なんでわざわざ?) 個のUnlabeledの点を(おそらくはランダムに)選ぶ。
- 選び出した各点に対して、Teacher Modelでラベルを推測し、それをpseudo labelとして扱って、Student Modelの訓練コーパスに重みをそのpseudo labelになる確率だとして、加えていく。
- Student Modelの重みをリセットして、訓練コーパス(先ほどからpseudo labelを付け加えたもの)で訓練する。先ほど定義したnoise-aware lossを使う。
- Teacher ModelのコーパスをStudent Modelのコーパスだとして更新する。
重ねて言うが、コーパス内の空でdないテキストを持つ各DOMノードに、その親が属するラベルとかをそのまま子につけている感じ?をやはりしている。
この手法は、Label-Efficient Self-Training LEASTという。
Experiment
実験では、
- 0-shot, few-shot extractionシナリオでどのように機能するのか
- 最先端のベースラインのモデルと比べて性能はどうか。
- WorkFlowにおける各部分の最終的な性能への影響はどうなのか。(いくつかの部分を削除しての性能を評価するテストをする)
評価指標はページレベルF1スコアとラベル効率(転移学習を利用して同じバックボーンモデルを訓練するために必要な人間によるラベル付けサンプル数と比較するらしい)
ちなみに最新のモデルはLSTMベースのSimpDOM、TransformerベースのMarkupLM Model。いずれもHTMLの解析に使っている。事前訓練と微調整の両方にLEASTを使う感じだ。ベースラインはいずれも人によるラベル付けのみだ。
比較は教師なし学習アルゴリズム Web-Extraction using Overlapping Data(WEIR)、教師ありのVisual Rendering-based Model(Render-FULL)、LSTMベースのDNNの手法であるSimpDOM。

↑コンポネントを外した時の性能低下。結局一番大事なのは、pseudo labelをつけてそれを使ってStudent Modelの訓練をすること。