
https://arxiv.org/abs/2303.05499
このブログが詳しいので、ここをベースに自分用のメモのための補足だけ。
https://blog.shikoan.com/grounding_dino/
Introduction
- Open Set物体検出=人間の入力によって、指定された任意の物体(未知でも)検出するというタスク。
- 先行研究はGLIPであり、CLIPをGroundに応用したものにあたる。
- 画像を与えられて、その中での物体の種類と、それの境界を表すBounding Boxを出力するようなモデル。
CNNによる物体検出
YOLOX
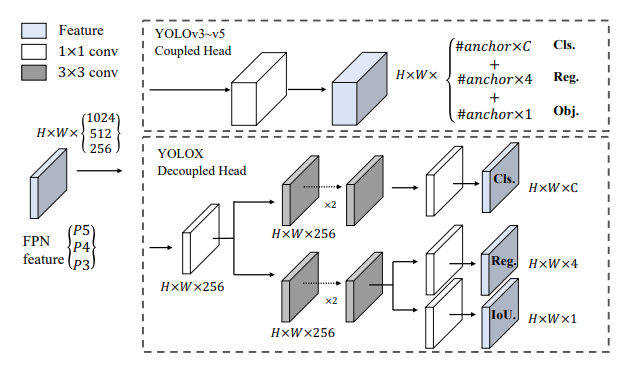
CNNは特徴マップの位置不変性があるので、まあ使える。
Transformerベースの物体検出(DETR)
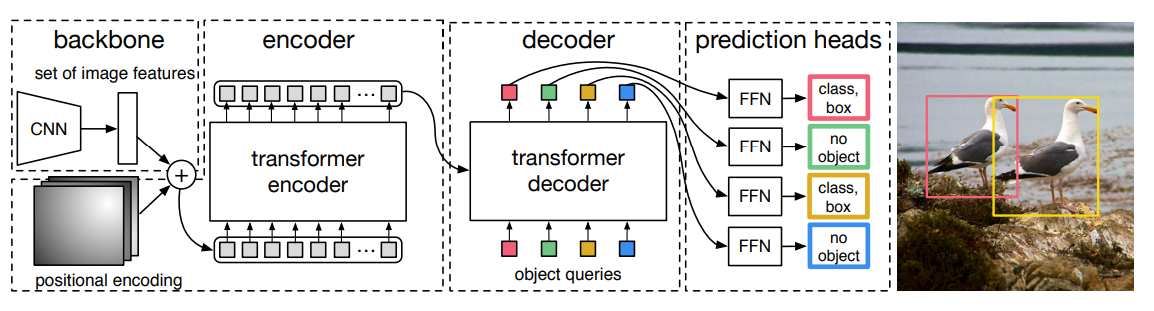
CNNで画像から特徴埋め込みを得て、そこに位置埋め込みも追加する。
次に、TransformerのSelf-attetionでEncoderを構成する。
Encoderで得た表現とどのように検出するのかのオブジェクトクエリと一緒にDecoderに入れる。
Decoderの出力を元に最終的にBounding Boxはどこどこなのか、クラスは何か?を出力する。
- DINOは、描述された言語を用いてみたことのない物体も検出するというもの(Closed Setにあるもの=見たことがある)
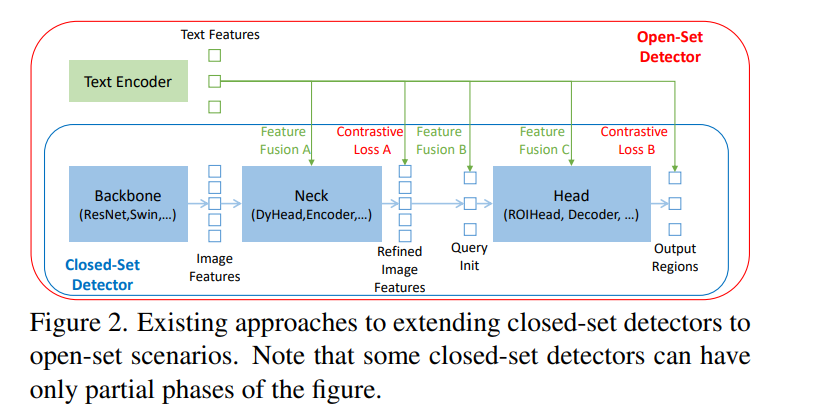
- Backboneは大規模なデータセットで訓練済のモデルで、画像の特徴ベクトルの抽出に使う。
- NeckはそこにText Encoderから得られた特徴と画像の特徴ベクトル(位置埋め込みはしてない!)を使って、混合した特徴ベクトルを作りたい。
- CLIPではここで比較学習をしてそれを元にLossとしてパラメタ更新をしていたが、ここでは比較学習しておらずImageとText(TransformerによるEncoder)の埋め込みを混ぜた混合した特徴ベクトルを得たい。
- 混ぜた後の特徴ベクトルと、Text Encoderの特徴ベクトルの比較学習をしたい。
- それのみならず、それより後のQueryの埋め込みなどにもText Encoderの出力を混ぜたりしている。
この研究の貢献
- 全部Transformerベースにして、早い段階から画像と言語を融合すると性能がどうも上がるらしいので、早い段階からその都度その都度混合をしている。
- 先行研究は、CLIPなどの0-shot学習で、特にClosedセットの物体検出の情報を使ってなかった。
- この論文は、事前に定義されたクラスセット=Closed Setについて学習させたもの。Closed Setで学習したものであっても、未知のものの検出に対してはそれなりの性能があるのでそれを利用した。
詳細なアーキテクチャ
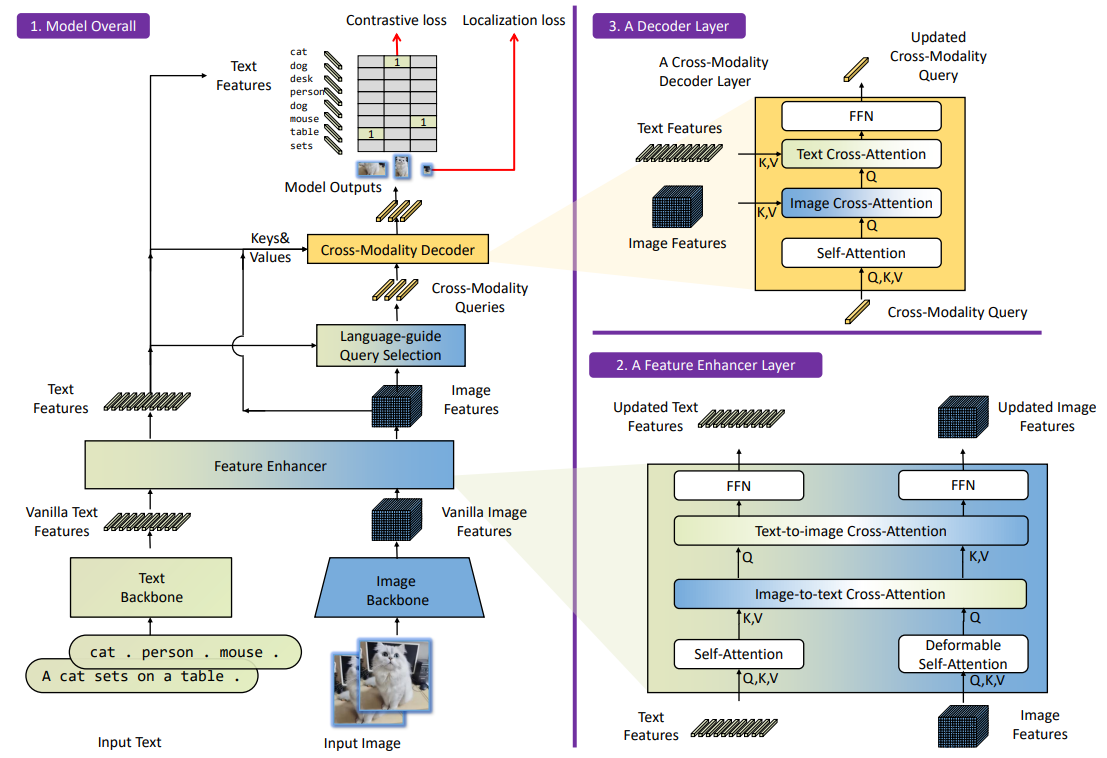
Model Overall
- TextをTransformerのEncoderから得られるText Embedding。
- ImageをBackboneによって、得られたImage Embedding(位置埋め込みなし)
- 1と2をFeature Enhancerに入れることで、「2つの特徴量を混ぜた混合特徴量」を作る。
- Feature Enhancerにあるように、Self-Attentionした後、Image to Text, Text to ImageでそれぞれCross Attentionをしている。
- これによって、特徴量はImageとTextの2つのままであるが、それぞれ相手方の情報を少し持つということを実現させている。これを特徴量を混合させているという。
- 最後にはFFNで、多層パーセプトロンで実現させている。
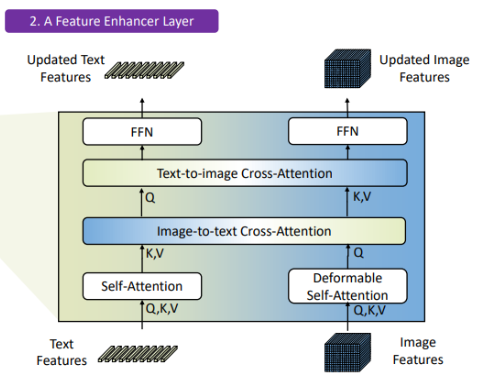
- 3の混ぜたあとのImage Featuresを準備する。
- 3の混ぜた後のText Featuresを準備する。
- これは後々各段階で、また混ぜ込む。
- Language Guide Query Selectionでは、どこを検出するのかなどの指示を含めた固定長のベクトルがQueryに当たる。4と5を混ぜてこれを得る。
- 例えば、「上側にある猫を探す」みたいな指示をベクトル化したのがQuery。
- 具体的には、4のImage Featuresの高次元データから、いくつかの低次元データを選び出す。
- 実装では、5のText Featuresとのcosine類似度が高い順に少数選んでいた。cosine類似度である必要自体はなさそう。
- これも人間が意味を付与しているってだけで普通に学習できる。
- これによって、Cross-Modality Queryを得る。
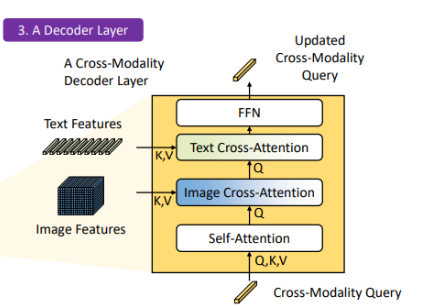
- 6-cで得たQueryに、再度4のImage Featuresと5のText FeaturesをCross-Modality Decoderに入れる。
- まずは6-cで得たQueryをSelf-Attentionする。
- 次に、Image FeaturesをK, Vに設定してCross-Attentionする。
- 次に、Text FeaturesをK, Vに設定してCross-Attentionする。
- 最後にはFFNで、多層パーセプトロンで実現させている。
- 出力は、更新されたCross-Modality-Queryである。
- 5のText Featuresと7のCross-Modality-Queryを最後に比較学習して、これを損失としてネットワークを更新する。