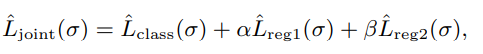https://arxiv.org/abs/2103.04685
Arxivにしかないので信頼度はある程度差し置いたほうがいい。
📄 2022-CVPR-[Dist-PU] Positive-Unlabeled Learning from a Label Distribution Perspective のMix-upがない版の研究である。これは一応書いたけどDist-PUでOKだが、最後のPseudo Labelの更新だけはモデルの出力するラベル分布予測の移動平均である。
2022-CVPR-[Dist-PU] Positive-Unlabeled Learning from a Label Distribution Perspective のMix-upがない版の研究である。これは一応書いたけどDist-PUでOKだが、最後のPseudo Labelの更新だけはモデルの出力するラベル分布予測の移動平均である。
Method
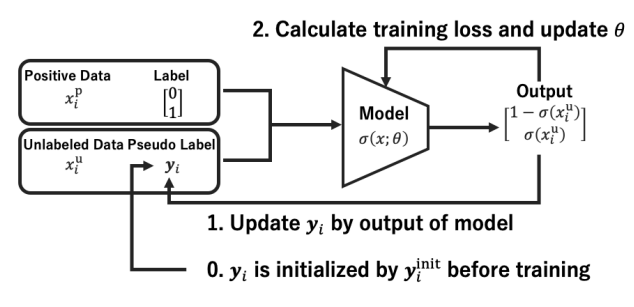
すべてのUにPかNのPseudo Labelを付与して、Noisy Labelの手法を用いて、そのPseudo Labelを更新していくことで最終的に学習器を訓練していく。
最小化する式は以下の通り
本体
本体は以下のようになる。Pに対するloss(これは明確にラベルがPだとわかるので)Lpと、UをNoisy Labelとみなして、sigmoid関数fでcalibrationした結果がPseudo Labelの連続値のyiと合致するようにしている。
Lclass(g)=λLP(g)+LU(g)LP(g)=E+[l(g(x),+1)]LU(g)=EX[DKL([yi1−yi]∣∣[f(g(xiu))1−f(g(xiu))])] 学習を進めるにつれて、λは大きい値から線形に1/nUまで減らすらしい。減らさないとこの手法の意味がない。
正則化
正則化項は2つ存在する。
まずは、calibrationして予測した結果の平均は、Class Priorと合致させないといけないというもの。これはあとの📄2022-CVPR-[Dist-PU] Positive-Unlabeled Learning from a Label Distribution Perspective とも同じidea。
Lreg1=EX[DKL([πP1−πP]∣∣[f(g(x))1−f(g(x))])] 次に、この予測結果をばらけさせたいので、Dist-PUと同様に、以下のものをつける。
Lreg=EX[f(g(x))logf(g(x))+(1−f(g(x)))log(1−f(g(x)))] Pseudo Labelの初期値とアップデート
すべてのUについて、初期のPseduo Labelはyi=πPと一律に設定。これはKL-Divergenceを最小化するもの。
更新については、モデルの過去数エポックの出力したラベル予測分布の平均をPseudo Labelとして更新する。